ページの先頭です
- ページ内移動用のリンクです
- ホーム
- IIJの技術
- セキュリティ・技術レポート
- Internet Infrastructure Review(IIR)
- Vol.68
- 4. フォーカス・リサーチ(3) 生成AIによる社内RAG基盤とマルチエージェント連携への拡張〜 実装技術と業務効率化の成果、今後の展望 〜
Internet Infrastructure Review(IIR)Vol.68
2025年12月
- 目次
4. フォーカス・リサーチ(3)
生成AIによる社内RAG基盤とマルチエージェント連携への拡張
〜 実装技術と業務効率化の成果、今後の展望 〜
4.1 はじめに
近年、OpenAIやGoogle、Anthropic社をはじめとする各社によってAI技術、とりわけ大規模言語モデル(LLM)の進化は著しく、企業における知識活用の方法は大きく変化しています。IIJにおいても2023年夏から、LLMを活用した社内専用のRAG基盤「sbdGPT」の運用を開始しました。本稿では、この社内RAG基盤の開発背景や目的、システム構成に加え、マルチエージェント化による拡張、更に社内RAG基盤と連携した提案書生成ツールについて述べます。
4.2 社内RAG開発の背景と目的
IIJでは100を超える法人向けサービスを展開しており、社内にはマニュアル、ナレッジ共有サイト、ニュース、問い合わせメールなど、多種多様な情報が大量に蓄積されています。これらの情報資産は複数の異なるプラットフォームに分散管理されているため、そこへ横断的にアクセスし、必要な情報を迅速に検索・取得することは、営業担当やエンジニアにとって大きな課題となってきました。その結果、繰り返し発生する社内問い合わせ作業や、情報探索に要する時間が現場の業務効率化を阻害していました。
こうした状況を背景に、社内に点在するドキュメントデータを収集・加工し、一元的にデータベースとして集約すると共に、生成AIを活用して質問内容に即した具体的な回答を提供できることを目指して、社内RAG基盤の開発に着手しました。
4.3 社内RAG基盤の構成とデータ最適化
社内RAG基盤は複数のデータソースを統合し、ベクトルデータ化してデータベースに格納しています。LLMや埋め込みモデル以外は自社サービス及びOSSを活用して、コストを抑えつつ開発アップデートや運用管理を自律的かつ柔軟に行える構成としています。
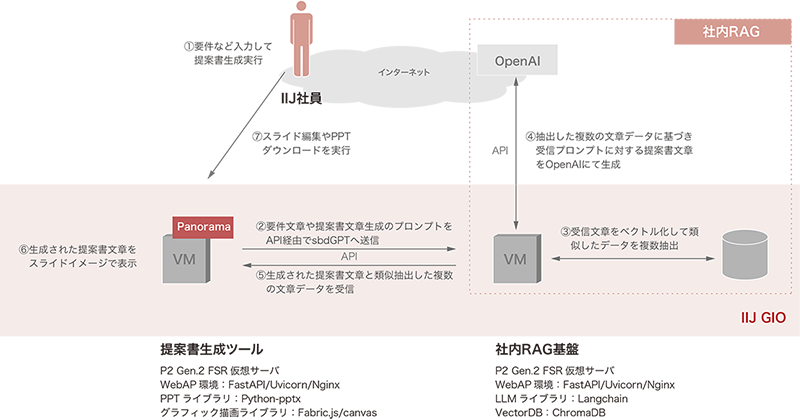
構成概要は図-1のとおりです。
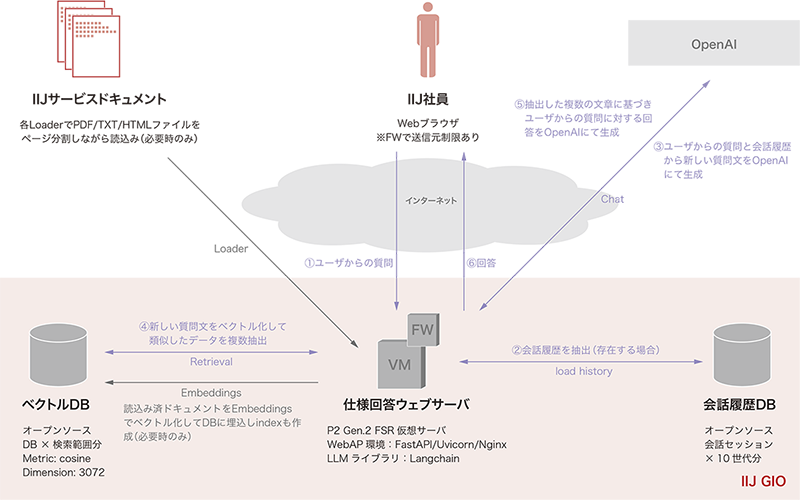
図-1 社内RAG構成概要図
- 構成要素
ナレッジベース(IIJサービスドキュメント)- サービス詳細資料(PDFファイル)- オンラインマニュアル(HTMLファイル)- 社内技術QAメール(メッセージファイル)- ナレッジ共有サイト(HTMLファイル)- ニュース記事(HTMLファイル)Webサーバ基盤- IIJ GIOインフラストラクチャーP2 Gen.2フレキシブルサービス仮想マシン- IIJ GIOインフラストラクチャーP2 Gen.2境界ファイアウォール- FastAPI(OSS)- Uvicorn/Gunicorn(OSS)- Nginx(OSS)生成AI/Embeddingモデル- OpenAI社製モデルLLM開発フレームワーク- LangChain(OSS版)ベクトルDB- ChromaDB(OSS版)会話管理DB- PostgreSQL(OSS版)
※生成AIとEmbedding以外は、IIJサービスのインフラやOSSを利用している。
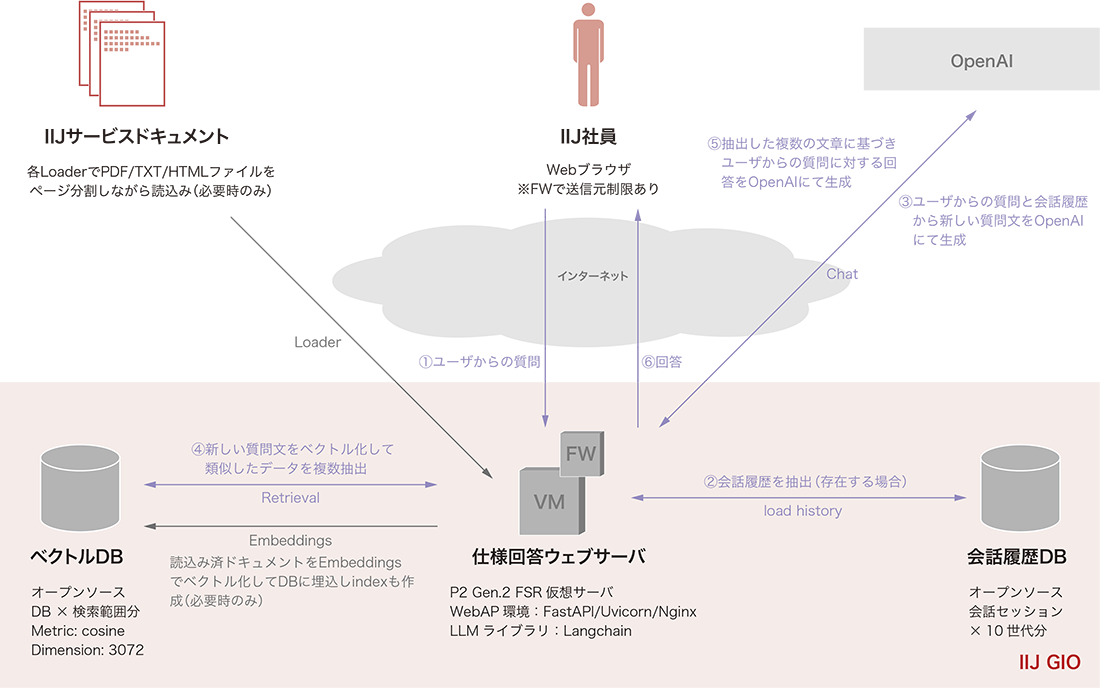
ベクトルDBに格納する各ナレッジデータは、複数のプラットフォーム上で分散管理されているPDFやHTMLなどのファイルを対象としています(図-2)。これらのデータは、ファイル形式ごとにLangChainが提供する各種Loaderを利用し、テキスト情報として抽出しています。
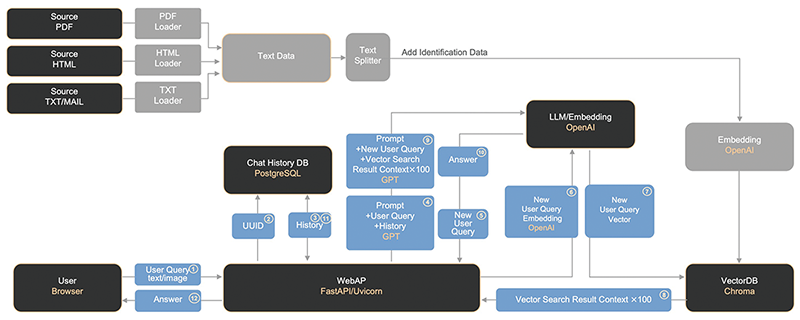
図-2 社内RAG動作フロー図
当初は一般的な手法に従い、抽出した大量のテキストデータをText Splitterで適切な長さに分割(チャンク化)し、そのままベクトルDBに格納していました。しかしこの方法では、ユーザクエリに対して期待する回答が得られないケースが多く発生しました。
原因を確認した結果、各サービスドキュメントはPDFやHTMLといったファイル単位で意味が完結しているため、部分的に分割抽出された短文(例:200文字程度のチャンクデータ)だけでは「どのサービスの、何に関する記述なのか」という文脈情報が不足し、ベクトル検索時に意味的類似(semantic similarity)が十分に機能せず、関連情報として正しく取得できない状況が生じていました。
この課題を踏まえ、チャンク化の際には各ファイルに記載されていた「サービス名」「タイトル情報」などの既存メタデータから識別情報を生成し、各チャンクに付与することで、ベクトル検索のヒット率及び回答精度の向上につなげています。
4.4 ファクトチェックに関する取り組み
AIの生成回答には、ハルシネーション(誤情報の生成)が含まれる場合があります。そのため、AIの回答を業務利用する際にはファクトチェック(根拠確認)が不可欠となっています。AIがどの情報を引用して回答を生成したのかを把握するには、AI自身に引用情報を出力させることが重要であり、ユーザはその引用情報を確認することで、内容の正確性を担保する必要があります。
ただし、ファクトチェックの操作が煩雑であれば、ユーザの利便性は大きく低下します。そこで本ツールでは、最小限の操作でデータソースにアクセスできる仕組みを導入しました。具体的には、生成回答の最後に表示される引用リンクボタンをクリックするだけで、読み込んだナレッジデータ(PDF・HTMLなど)のソースを表示するように実装しています。
HTML以外のデータソースについては、事前にWebサーバ内に格納し、ブラウザ経由で静的に公開することで、PDFなどのソースにも即座にアクセス可能としました。この仕組みにより、AI回答の信頼性を確認するための導線を簡素化しています。
更に、各チャンクに付加している識別情報には、データソースファイルのFQDN(PDFの場合はページ番号を含む)も付与しています。そのため、システムプロンプトでは以下のような引用情報の出力形式を指定し、生成回答の直下に引用元を明示するようにしています。これにより、利用者はボタンをクリックするだけで、引用情報をテキスト表示し、Webサーバ上のソースファイルへも即時アクセスできます。

4.5 業務効率効果とRAG基盤のマルチエージェント拡張
社内RAG基盤の利用を2023年夏に開始して以来、約2年間の運用を経て、月間約3万クエリが処理されるまでに利用が拡大しました。これにより、社内で月当たり約1,500時間相当の業務効率化が実現しつつあります。
一方で、運用を重ねる中で、RAG単体では社内情報に基づく回答に限界があることも明らかになりました。特に、最新の市場動向や競合比較、外部製品との仕様差分など、インターネット上の情報を参照しなければ適切な回答が難しいケースが増え、また、単なる仕様確認にとどまらず、営業担当やエンジニアによる市場リサーチやトレンド分析など、より高度な意思決定支援を行う必要性も出てきていました。
こうした課題を解消するため、社内RAG基盤を拡張し、複数の専門エージェントが連携して応答を生成するマルチエージェント構成を実装しました。従来のRAGは、IIJサービスのマニュアル、ナレッジ共有サイト、問い合わせメールなど社内データをベクトルデータベース化し、生成AIによって回答を生成する仕組みでしたが、社内データのみでは「IIJと他社のサービス仕様比較」や「最新技術トレンドに基づく提案検討」といった外部情報を必要とするクエリへの対応が困難でした。
この制約を解決するため、従来の社内RAG基盤をリファクタリングし、マルチエージェント型の基盤を構築しました。メインエージェントがルーティングロジックに基づいて、社内RAG基盤のエージェント版となる「IIJ Service Agent」や最新の外部情報を取得する「WebSearch Agent」を必要に応じて自動的に呼び出す仕組みです。
具体的な制御構成としては、LangGraphによる状態遷移グラフを用いてエージェント間の連携を統合的に管理しています。メインエージェントは質問文章を解析し「社内データで解決可能か」「外部情報が必要か」を判定した上で、該当するサブエージェントを呼び出します。サブエージェントの処理結果はメインエージェントに返却され、最終的に統合された応答文章としてユーザに出力されます。これにより、社内情報と外部の最新情報を組み合わせた包括的な回答生成が可能となりました。
更に、サブエージェントは並列実行にも対応しており、複数の情報領域の処理を同時に実行できるため、人力では実現できない速度で結果を出力することができます。加えて、LLMの推論過程を可視化することで処理の透明性も高めています。UI上では「どのエージェントが呼び出されたか」「どの情報源に基づいて回答が生成されたか」がストリーミングで逐次表示され、利用者はLLMの推論過程をリアルタイムで追跡できるようになっています。
結果として、従来の社内RAG基盤ではカバーしきれなかった領域まで回答範囲を拡張することができ、ユーザエクスペリエンスの大幅な改善につながりました。マルチエージェント化によって構築された社内エージェント基盤は、単独では解決困難だった情報不足の問題を克服し、AI活用の幅を大きく広げる重要なステップとなっています。
4.6 DeepResearchとRAGの融合
2024年末にGoogleが発表したDeepResearchは、インターネット上の膨大な情報源を自律的に探索・分析・統合し、研究者やアナリストのように多段階の調査を遂行できる仕組みとして注目を集めました。その後、2025年2月にはOpenAIからもDeepResearchがリリースされ、同年6月にResponses APIとして提供が開始されたことで、既存のエージェント環境に組み込める実用的な材料が整いました。
DeepResearchの最大の特徴は、「計画 → 検索 → 吟味 → 統合 → 生成」という一連のプロセスを自動的に繰り返す点にあります。Web検索を複数回行い、取得した情報を検証しながら再計画を立て直し、最終的に信頼性の高い要約レポートを返す。そのため処理完了には30分程度を要する場合もありますが、技術文献レビューや競合・市場調査、規制比較など、高い網羅性と根拠が求められる調査分野において強力な武器となります。
社内エージェント基盤では、LangChainとLangGraphにより既にマルチエージェント構成を実装していたため、DeepResearchをサブエージェントとして追加することは比較的容易でした。具体的には、@toolでDeepResearchエージェントを定義し、その内部でResponses APIを呼び出す関数を実装する形で統合しました。ユーザからのクエリを受け取ると、DeepResearchはWeb検索を複数回実行し、必要に応じて数段階の推論と統合を経て、レポート・データ表・出典リストを含む構造化された応答を返します。
加えて、ClarifyQuery(質問の明確化)エージェントをDeepResearch前段に配置する仕組みも導入しました。これは、曖昧なクエリがそのままDeepResearchに渡されることで、検索の再試行が増え、結果としてコストや処理時間が膨大になってしまうことを防ぐためのものです。このエージェントは、利用者の質問内容を確認し、必要に応じて追加の確認質問を行うことでクエリを明確化し、その上でDeepResearchを実行します。これにより、利用者の意図に沿った網羅的かつ効率的なリサーチが可能となっています。
また、DeepResearch APIが提供する推論パラメータ(summary、effort、verbosity)をユーザが調整できるようにし、調査の深さや出力量を用途に応じて選択できる仕組みを整えました。例えば、エグゼクティブ向けの短い要約を求める場合はeffort=low、verbosity=lowを選択し、仕様比較のような綿密な調査にはeffort=high、verbosity=highを指定することで、同じクエリでも出力粒度をクリック操作だけで柔軟にコントロールできるようにしました。
UI上では、処理の進捗やコストも可視化しています。AIの推論過程をストリーミング表示するほか、使用トークン数やモデルの消費コストを集計表示することで、利用者は回答生成に要したコストを把握できるようになり、更に開発者としてはトークン消費量やキャッシュトークンの使用状況をモニタリングできるので、ツールの最適化に向けた情報として活用しています。
こうしたDeepResearchの導入を進める中で新たに浮かび上がったのは、「社内データも含めた自律的なリサーチ機能の必要性」でした。通常のDeepResearchはインターネット上の公開情報を主な対象として設計されており、すべての社内ナレッジベースと直接連携する仕組みは備えていませんでした。また、社内ナレッジサイトについても、提供されているAPIを経由すればDeepResearchとの接続自体は技術的に可能と考えられましたが、社内調整や承認といった非技術的なハードルが高く、現実的ではありませんでした。
そのため初めに取られたアプローチが、IIJ Service Agent(社内RAG)とWebSearch Agentを組み合わせ、プロンプトで細かく処理ステップ手順を制御する方法でした。インターネット上の最新情報はWebSearch Agentが、社内情報はIIJ Service Agent(社内RAG)がそれぞれ探索し、最終的にその結果を統合してユーザに返すことが可能となりました。ただ、従来のLLM(GPT-4.1以前)では、推論ステップの制限やツール呼び出し制御の弱さにより、十分な網羅性と整合性を確保することが困難でした。
そこで、開発検証の最中にリリースされた、エージェントタスク処理に最適化されたといわれるGPT-5をメインエージェントとして適用しました。GPT-5はツール呼び出し、命令遵守(instruction following)、ロングコンテキスト理解、ツール呼び出し間の推論保持といった能力が強化されており、これによりエージェントワークフローにおけるツールとの連携性が大幅に向上しました。結果として、各サブエージェントを複数回呼び出しながら網羅的に情報を収集し、社内データを含む30〜80件程度の引用情報を基に最適な回答を生成できるようになりました。
これにより、従来は「情報不足」と判断されたクエリに対しても、社内データと外部情報を横断的に活用した高い網羅性と信頼性を備えた回答を提供できるようになり、大きな進展を得ることとなりました。また、開発者としても、既存アーキテクチャを大きく変更することなく最新のLLMを適用するだけで課題を解消できた点は重要であり、エージェント基盤の拡張性と継続的進化の可能性を実感するポイントでもありました。
4.7 提案書生成ツールの開発
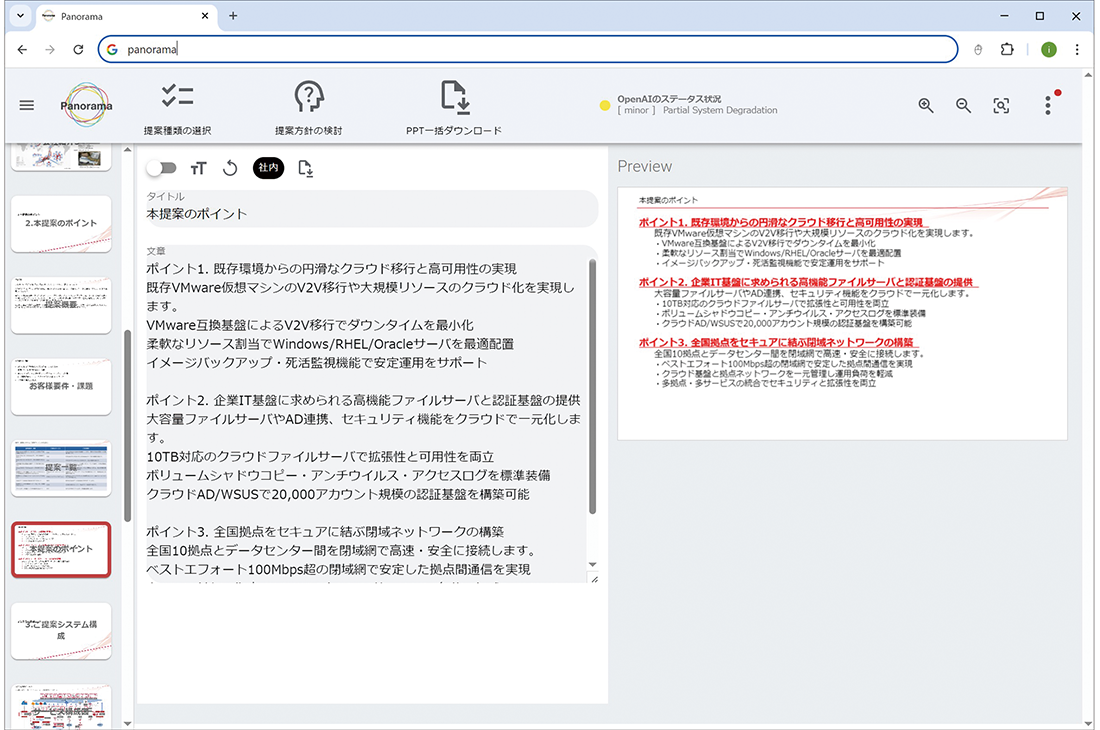
社内RAG基盤の運用が安定した段階で、新たなWebアプリとして提案書生成ツール「Panorama」の開発が進められました。営業担当やエンジニアが要件に応じてPowerPoint形式の提案書を作成する業務は、社内テンプレートからスライドを選別・編集する手作業に多くの時間を要していました。こうした課題を解決するために開発されたのが本ツールであり、要件入力から提案書ドラフトの自動生成までを簡単な操作で行える仕組みを提供しています(図-3)。
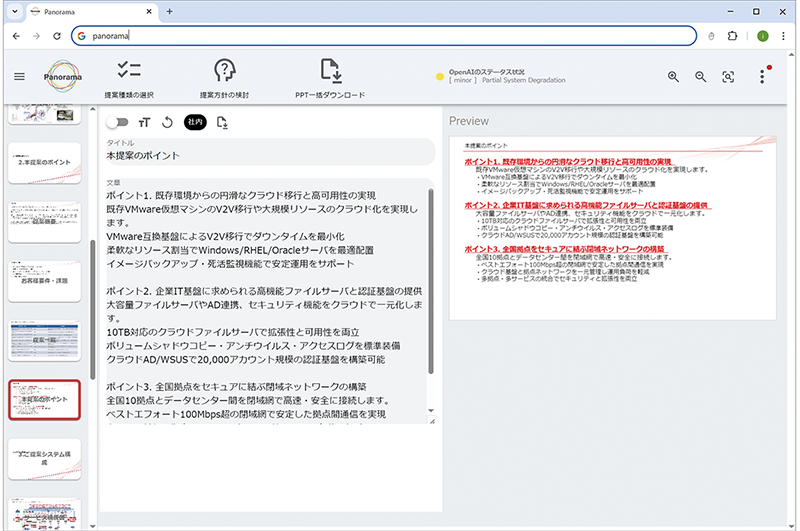
図-3 提案書ツール利用者画面
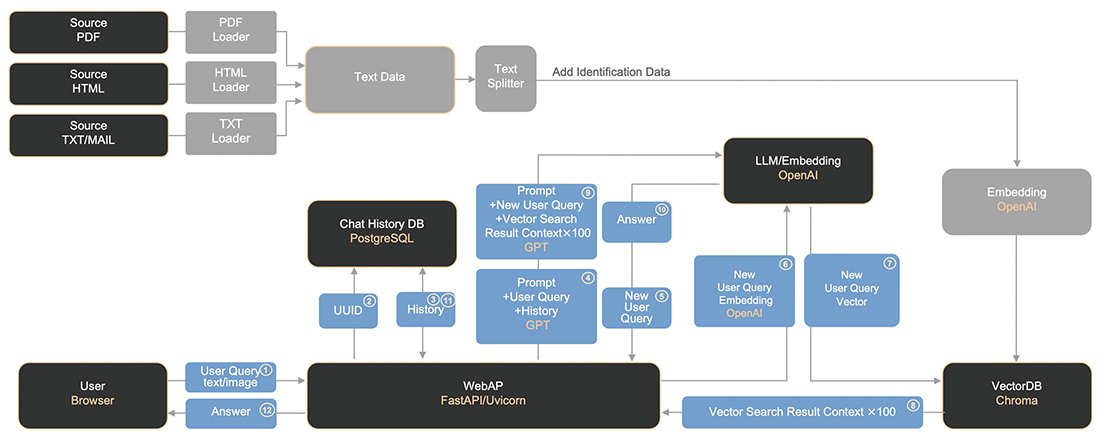
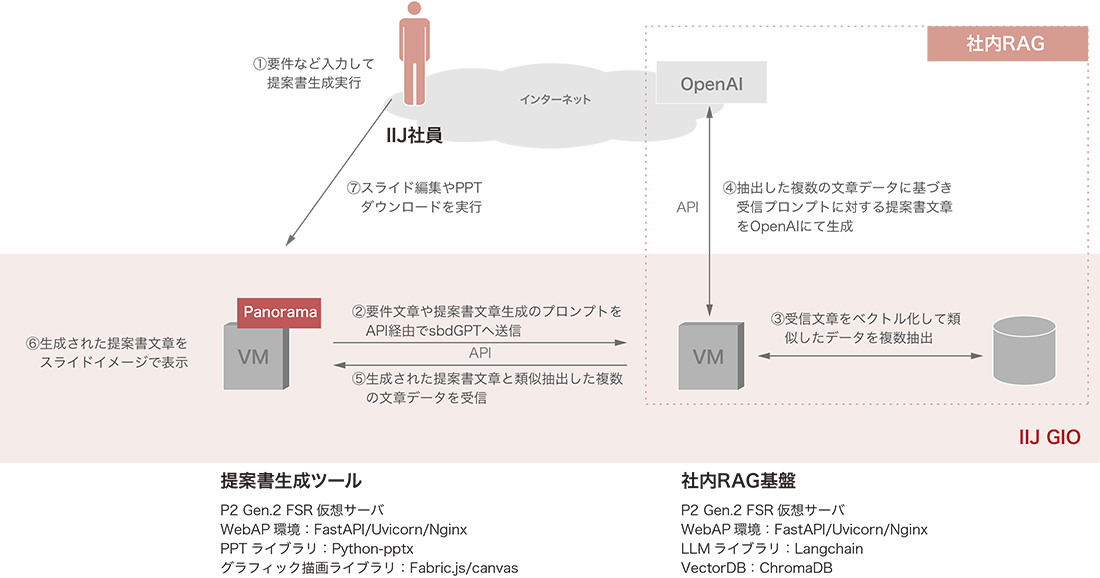
提案書生成ツールは、ユーザがブラウザ上で要件や希望サービスを入力して実行すると、Webサーバが社内RAG基盤のAPIを呼び出し、入力データとシステムプロンプトを基にして最適なサービス提案文面を自動生成させる仕組みを備えています(図-4)。生成結果はスライド単位の構成情報としてJSON形式で処理され、ブラウザ上の編集画面に反映されると共に、プレビュー用のHTML5 Canvas上にリアルタイムで描画されます。描画編集にはfabric.jsを用いており、ユーザはブラウザ上で構成図レイアウトや提案文面を確認・修正しながら、最終的にPowerPointファイルとしてダウンロードできます。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
図-4 提案書ツールシステム構成概要図
技術的には、Vue.js+fabric.jsによるフロントエンドと、FastAPI+python-pptxによるバックエンドで構成されています。フロントエンド側では、スライドや構成図の編集内容をリアルタイムに反映し、すべての編集データをJSON形式で一元管理します。これらのデータはFastAPIを介して送信され、バックエンドのPPTXファイルの生成処理に利用されます。バックエンド側では、JSONデータを基にPythonでテンプレートスライドに対応するXML構成ファイルを操作・更新し、その編集結果を基にpython-pptxライブラリで最終的な提案書ファイルを生成します。
これらの仕組みにより、AIが生成した提案文章や自動プロットした構成レイアウト図をスライドに反映し、編集作業を最小限に抑えつつ、一定した品質の提案書を短時間で作成することができます。更に、社内RAG基盤との連携により、提案文章にはIIJサービスの仕様や提案理由、提案ポイントなどの社内ナレッジが自動的に反映されています。編集画面には参照元情報が明示され、クリック操作でデータソースを即時確認できるため、提案内容のファクトチェックも容易です。
今後はテンプレートスライドを順次追加し、PDF形式でのエクスポートや構成図編集機能の強化など、機能拡張を予定しています。
4.8 今後の展望
最新の言語モデル及びエージェント技術の進化により、複雑な処理の自律実行が現実のものとなり、業務自動化や効率化を支える基盤としてエージェントの重要性が急速に増しています。
当面は、利用ニーズを見極めながら特定業務に特化したツールを順次開発・登録し、本AIエージェント基盤の機能を継続的に拡充していく予定です。また、AIが参照・引用するデータソースの作成元へのインセンティブと、引用頻度の向上が相互に循環すべく仕組みの検討を進めます。
中長期的には、ローカルLLMを活用して自社インフラ内で完結する構成へ移行し、IIJの多様なサービスと連携したパッケージとして、お客様に提供できる環境の実現を目指していきたいと考えています。
執筆者プロフィール

海老根 和徳(えびね かずのり)
IIJネットワークサービス事業本部 システム開発本部 AIプラットフォーム推進室
2005年IIJ入社。公共・民間向けシステム構築に従事し、要件定義から設計・構築・運用まで幅広く担当。クラウドサービスの提案・導入や技術体制整備を通じて売上拡大に貢献。副部長・室長としてAI活用による業務効率化や部門横断施策を牽引した後、現在はAI基盤の開発・企画を推進している。
- 4. フォーカス・リサーチ(3)
生成AIによる社内RAG基盤とマルチエージェント連携への拡張〜 実装技術と業務効率化の成果、今後の展望 〜
ページの終わりです