ページの先頭です
- ページ内移動用のリンクです
- ホーム
- IIJの技術
- セキュリティ・技術レポート
- Internet Infrastructure Review(IIR)
- Vol.68
- 2. フォーカス・リサーチ(1) DNSフルリゾルバbowlineの設計と実装
Internet Infrastructure Review(IIR)Vol.68
2025年12月
- 目次
2. フォーカス・リサーチ(1)
DNSフルリゾルバbowlineの設計と実装
IIJでは、DNSフルリゾルバ(別名キャッシュDNSサーバ、以下単にフルリゾルバ)を独自に開発しています。ソフトウェアの名前はbowlineです。「結びの王様」である「もやい結び」から名付けました。現時点では、ロギングやモニタリングなどISPでの運用に必要な機能のほとんどを実装し終えており、試験的な運用を通じて安定性を検証しています。この記事では、bowlineの設計と実装について述べます。
IIJは、フルリゾルバの複数の実装を用いて、キャッシュDNS サーバを提供しています。bowlineの狙いの1つは、独立した実装を増やし、攻撃に対して耐性を向上させることです。また、IIJ が完全にコントロールできることもポイントです。コントロール下にあれば、新たな攻撃方法に対する対策を素早く実装し、稼働しているサーバを置き換えることが可能なはずです。
bowlineはオープンソースとして公開しており、実装言語はHaskellです。Haskellを利用する理由は、「HaskellによるQUICの実装」(注1)の3.2節「Haskellで実装する理由」を参照してください。一番大切なのは、Haskellでは軽量スレッド(以下単にスレッド)が提供されているので、イベント駆動プログラミングに比べて、ソフトウェアを柔軟かつ見通しよく構成できることです。
2.1 開発の経緯とライブラリ群の構成
著者は、2010年にアンチスパムの取り組みとして、SPF、Sender ID、DomainKeys、及びDKIMを統合するフレームワークをHaskellで実装しました。これらの技術を利用するには、DNSを検索する機能が必須です。当初は、C言語で書かれた有名なDNSスタブリゾルバ・ライブラリを他言語関数インタフェース(FFI)を通じて使用していましたが、Haskellの高度な並行処理の下では、表明違反が多発し、うまく動かないことが判明しました。
そこで、このライブラリの利用を諦め、完全にHaskellのみで書かれたDNSスタブリゾルバ・ライブラリ(名称はdns)を開発しました。すべてをHaskellで書けば、言語の特性から、高度な並行性は自動的に実現されます。事実、その実用性が複数のインターネット・サービスを通じて実証されました。
bowlineの開発は、同僚の日比野と共に2022年から始めました。フルリゾルバの主要な機能である反復検索、キャッシュ、及びDNSSEC検証は日比野が担当しました。著者は2013年からHaskellで、HTTP/2、TLS 1.3、QUIC、及びHTTP/3のライブラリを開発しており、それらをDNSに応用することに興味があったので、主にトランスポートを開発しました。
bowlineの原型ではdnsライブラリを利用していましたが、これまでの経験から、dnsライブラリには拡張性がなく、またメモリが断片化する問題のあることが分かっており、これらの欠点を下位互換性を気にすることなく解決できるよう、新たにDNSライブラリ群を開発することにしました。機能ごとに分割されたライブラリ群は、すべてdnsextという接頭辞から始まり、それぞれ以下のような機能を提供しています。
- dnsext-types:拡張可能で断片化しない基本データ型及び基本RR(Resource Record)の符号器/復号器
- dnsext-dnssec:DNSSEC関連のRRの符号器/復号器、DNSSECの検証器
- dnsext-svcb:最近仕様が決まったSVCB(Service Binding)RRの符号器/復号器
- dnsext-utils:ログやキャッシュなどユーティリティ関数
- dnsext-do53:クライアント側のDNS over UDP、TCP
- dnsext-dox:クライアント側のDNS over HTTP/2、HTTP/3、TLS、QUIC
- dnsext-iterative:反復検索アルゴリズム、サーバ側のDNS over UDP、TCP、HTTP/2、HTTP/3、TLS、QUIC
- dnsext-bowline:フルリゾルバbowline、DNS検索コマンドdug(注2)、暗号化されたDNSサーバの探索を実現するデーモンddrd(注3)
dnsext-dnssecやdnsext-svcbは、dnsext-typesが拡張できることの例となっています。
2.2 スレッドの構成
一般的に、フルリゾルバは、以下のように動作することが期待されています。
- スタブリゾルバから、再帰検索(Recursion Desiredフラグがオン)の要求を受け取る
- 要求に対してキャッシュを検索し、「肯定応答」あるいは「否定応答」が存在すれば、スタブリゾルバに返す
- 存在しなければ、権威サーバに対して反復検索(Recursion Desiredフラグがオフ)を繰り返し実行し、肯定応答あるいは否定応答を得てスタブリゾルバに返し、新たなエントリをキャッシュに登録する
ネットワークを利用する反復検索は、メモリ操作であるキャッシュの検索よりも圧倒的に時間がかかります。そこで、反復検索が他の要求や応答の処理に悪影響を及ぼさないようにソフトウェアを設計する必要があります。
歴史的にDNSのトランスポートには主にUDPが使われており、同一スタブリゾルバから複数の要求を受けた場合、解決できたRRから応答を返します。一方、コネクション型のトランスポートでは、スタブリゾルバが送った順番どおりに、フルリゾルバが要求を受け取ります。応答を順番どおりに返そうとすると、ある要求に対する反復検索が後続の要求をブロックしてしまうことがあります。これを防止するために、コネクション型のトランスポートでは、先に解決できた要求に対する応答から返すことが求められています(パイプライニング)。つまり、コネクション型のトランスポートでも、UDPと同じように振る舞う必要があるのです。
仮に、1つのスレッドがキャッシュと反復検索の両方を担当するように設計したとしましょう。このスレッドは、反復検索でブロックされる可能性があります。そのため、後続の要求を滞りなく処理するためには、要求ごとに、このスレッドを生成する必要があることが分かります。このような設計では、主機能を司るこのスレッドの数が膨大になる可能性があり、脆弱です。
そこで、キャッシュを検索するスレッド(以下、キャッシュ検索器)と反復検索をするスレッド(以下、反復検索器)を別々に用意することにしました。キャッシュ検索器は、キャッシュの検索に失敗した場合、反復検索を反復検索器に任せます。キャッシュ検索器はブロックされませんが、反復検索器はブロックされる可能性があります。キャッシュ検索器と反復検索器は、サーバの起動時に固定数が生成されます。反復検索器の数がキャッシュ検索器の数よりも十分に大きければ、スムーズなパイプライニングが実現できます。
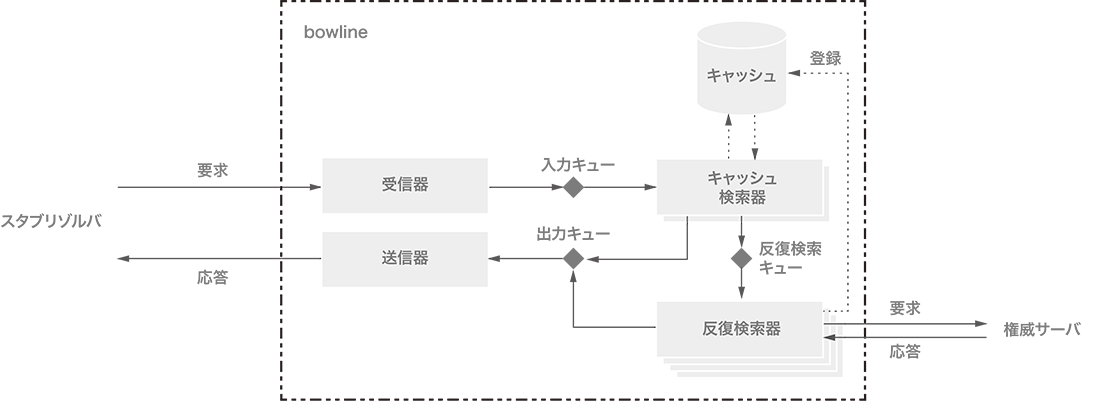
以上の考察の下に設計したスレッドの構成を図-1に示します。二点鎖線の四角がbowline全体を表し、灰色の四角がスレッドを表現しています。トランスポートを担当するのは受信器と送信器です。この組は、UDPに対してはネットワーク・インタフェースの数だけ常駐します。コネクション指向のトランスポートでは、ネットワーク・インタフェースの数だけ待ち受けスレッドが常駐し、コネクションが作成されるたびに受信器と送信器の組が生成されます。HTTP/2、QUIC、HTTP/3に関しては、補助的なスレッドも起動されます。
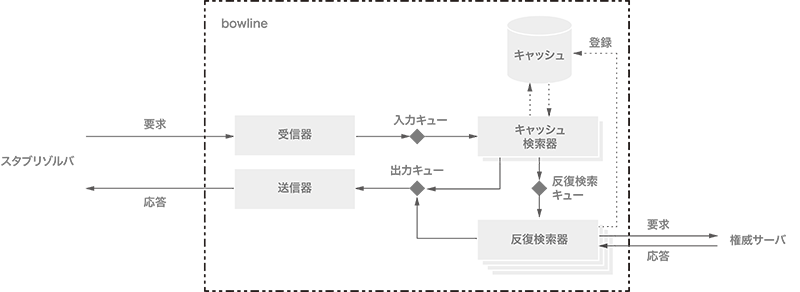
図-1 bowlineのスレッドの構成
受信器は、スタブリゾルバからのDNS要求を復号し、InputというHaskellのデータ型に変換後、グローバルな入力キューに入れます。Inputにはその受信器に対応する送信器の出力キューへの参照が格納されています。
キャッシュ検索器は、グローバルな入力キューからInputを受け取り、キャッシュを検索します。この動作はブロックされません。検索に成功すれば、結果をOutputというデータ型で表現して、Inputから参照されている出力キューへ格納します。失敗すれば、グローバルの反復検索キューにInputをリレーします。bowlineのデフォルトでは、キャッシュ検索器の数は4個です。
反復検索器は、反復検索キューからInputを読み出し、反復検索を試みます。この動作はブロックされる可能性があります。すべての反復検索器がブロックされると反復検索の機能全体がブロックされるので、反復検索器の数は十分に大きくする必要があります。反復検索器は、反復検索で得られた結果をOutputで表現し、出力キューに格納します。bowlineのデフォルトでは、反復検索器の数は128個です。
送信器は、自分用の出力キューからOutputを読み出し、DNS応答へ符号化した後、スタブリゾルバへ送信します。
2.3 反復検索アルゴリズム
DNSの権威サーバは、クライアントからの要求に対して以下のように振る舞います。
- 自分が管理するゾーンのドメイン名であり、問い合わせRR型のRRが存在すれば、その値を返す
- 自分が管理するゾーンのドメイン名であり、問い合わせ名が存在しない、あるいは問い合わせRR型のRRが存在しない場合は、SOA RRを返して、否定応答をキャッシュするためのTTLを提示する
- 自分が管理するゾーンのドメイン名であり、下位ゾーンの委任情報が存在するなら、リゾルバが反復検索を続けられるように、下位ゾーンの委任情報(NS RR)やグルー(A RRやAAAA RR)を返す
反復検索では、フルリゾルバは、権威サーバに対するクライアントとして振る舞います。RFC 1034で定義される反復検索では、それぞれの問い合わせ名と問い合わせRR型は、スタブリゾルバが指定した値に固定されていました。
例えば、スタブリゾルバからwww.example.jpのTXT RRの解決を依頼されたとします。フルリゾルバは、最終的に"example. jp."の権威サーバにwww.example.jpのTXT RRを問い合わせるのと同様に、ルート(".")の権威サーバや、中間の"jp."の権威サーバにも同じ要求を使います。
この仕組みは、インターネットの盗聴者に対して、オリジナルの問い合わせ名や問い合わせRR型を盗聴させる機会を多く与えていると言えます。そこで、プライバシ保護の観点から、「問い合わせ名最小化」が提案されました。問い合わせ名最小化では、オリジナルのドメイン名の必要な部分のみを用いて権威サーバに問い合わせます。また、中間で利用する問い合わせRR型には、RFC 7816ではNS RR、RFC 9156ではA RRかAAAA RRを用います。
表-1に、www.example.jp.のTXT RRを解決する際の問い合わせ名と問い合わせRR型をまとめます。bowlineは、反復検索としてRFC 9156で定義される「問い合わせ名最小化」のみを用います。表-1のRFC 9156の列を以下で詳細に説明します。
- "."の権威サーバに"jp."のA RRを問い合わせ、"jp."の権威サーバを得る。
- "jp."の権威サーバに、"example.jp."のA RRを問い合わせ、"example.jp."の権威サーバを得る。
- "example.jp."の権威サーバに、"www.example.jp."のA RRを問い合わせると、答えが得られるため、更なる委任がないことが分かる。
- "example.jp."の権威サーバに、"www.example.jp."のTXT RRを問い合わせる。
表-1 問い合わせ名最小化の例

最後に冗長に思える検索が起こるのは、オリジナルの問い合わせRR型を隠しながら、委任がないかを調べるためです。オリジナルの問い合わせRR型とアルゴリズムで用いられるRR型がたまたま一致した場合は、検索回数が1回減ります。
問い合わせ名が正常に存在するのであれば、どの段階でも得られる権威サーバ名は1つ以上あり、各々の権威サーバには1つ以上のA/AAAA RRが存在します。前述のように、グルーとしてA/AAAA RRが、NS RRと一緒に返される場合があります。
2.3.1 反復検索の実装
bowlineがスタブリゾルバから要求を受け取り、クライアントとして権威サーバに対して反復検索を実行する際は、まずルート・プライミングを実行します。ルート・プライミングとは、あらかじめ組み込まれている"."の権威サーバの候補(ヒント情報)に対して、"."の最新のNS RRを問い合わせ、A/AAAA RR も同時に解決することです。この結果は、キャッシュされます。よって有効期限内であれば、これ以降の要求からはキャッシュの値が利用されます。
この特殊な処理が完了すれば、以降は最終の答えを得るまで、以下のステップを繰り返します。まず、IPアドレスが分かっている権威サーバと、分かっていない権威サーバのグループを作ります。
次に、IPアドレスが分かっている権威サーバに対し、IPアドレスをランダムに並べ替え、権威サーバの名前が重ならないように2つを取り出します。そして、問い合わせ名最小化のアルゴリズムに従った要求を、権威サーバに並列実行で問い合わせます。
我々の実装では、このクライアントの機能はdnsext-do53ライブラリで提供されており、複数のサーバに対して問い合わせスレッドをそれぞれ生成して競争させ、一番最初に返ってきた応答を採用することができます。
問い合わせに失敗した場合は、次の2つの候補に移ります。IP アドレスが分かっている権威サーバの問い合わせにすべて失敗した場合は、IPアドレスが分かってない権威サーバに移ります。この段階では、ランダムに並べ替えた権威サーバの先頭1 つに対して、ランダムにA RRかAAAA RRを選んで、権威サーバの名前に対する新規の反復検索を実行します。解決できなければ、次の名前に進みます。解決できたら、そのIPアドレスの1 つに対して、このステップの目的の問い合わせを実行します。
すべてが失敗したら、全体として検索の失敗なので、スタブリゾルバにエラーを返します。いずれかが成功した場合、完全マッチで対象のRRが手に入れば、そこで反復検索は完了です。そうでなければ、下位の権威サーバの名前が手に入っているので、一段長い問い合わせ名を用いて、このステップを繰り返します。
2.3.2 反復検索のエラーケース
NODATAは、ドメイン名は存在するがRR型に該当する値がなく(他のRR型の値は存在する)、次に問い合わせるべき権威サーバもないエラーです。問い合わせ名全体を渡すRFC 1034のアルゴリズムでは、NODATAが返れば、それが最終結果です。しかし、問い合わせ名最小化のアルゴリズムでは、問い合わせ名を長くして検索を続ける必要があります。例えば、".jp."の権威サーバに、"ad.jp."を問い合わせるとNODATAですが、"iij.ad.jp."という問い合わせに対しては権威サーバの情報が返ってきます。これは、"jp."と"ad.jp."が同一のゾーンであるためです。
NXDOMAINは、ドメイン名が存在しない場合のエラーです。ある中間ドメインがNXDOMAINとなれば、RFC 8020が定める仕様としては、それより以下にドメインが存在しません。しかしながら現実的には、下位のドメインを検索するとドメインが存在する場合があります。このためbowlineでは、中間ドメインがNXDOMAINとなってもドメイン名を長くしながら検索を続けます。最終的に、問い合わせ名がNXDOMAINとなった場合にのみ、このエラーと判定します。
SERVFAILはサーバの障害、REFUSEDは何らかの理由で問い合わせが拒否されたこと、FORMERRは書式違いを表すエラーです。これらのエラーが起こった場合、次のIPアドレスの候補にフォールバックして検索を続けます。
2.3.3 dugによる可視化
前述のdugは、2つのモードを持つDNS検索コマンドです。一方のモードは、単なるスタブリゾルバとして、フルリゾルバに再帰検索を依頼します。権威サーバに対して、Recursion Desiredフラグをオフにして問い合わせることもできます。
他方のモードは、bowlineと同じ反復検索の実装を使って、その様子を可視化します。右カラムの枠内は、dugを使った反復検索の例です。-iが反復検索モード、-vvが表示量を増やすオプション、+cdflag(check disabled)がDNSSECの検証を止めるフラグです。
候補の権威サーバのIPアドレスのうち、実際に利用されたものは"(※番号)"を加筆しています。"win"は2つの競争する検索のうち、どちらが勝ったかを表します。委任があればIPアドレスが一覧表示され、そうでなければ"no delegation"と表示されます。

2.4 DNSSECの反復検索アルゴリズム
DNSSECでは、公開鍵暗号技術の1つである電子署名を用いて、委任情報に対する認証の連鎖を構築します。あるゾーン内でのDNSSECに関連するRRは、以下の2つです。
- DNSKEY:そのゾーンから提供される電子署名(RRSIG)を検証するための公開鍵(DNSKEYには、鍵署名鍵とゾーン署名鍵が含まれますが、この記事では区別しません)
- RRSIG:そのゾーンが管理しているRRに対する電子署名
DNSKEY RRを使ってRRSIG RRを検証すれば、データに改ざんがないことが分かります。しかし、名乗っているドメイン名が本当に正当であるのかは分かりません。このため、上位のドメインから委任されていることを証明する必要があります。そこで、以下のRRが用意されています。
- DS:あるゾーンのDNSKEYに対する暗号学的ハッシュ値を上位のゾーンに登録するためのRR
DO(DNSSEC OK)フラグがオンの反復検索の要求に対して、権威サーバは以下のように振る舞います。
- 下位ゾーンへの委任がある場合:NS RRなど委任情報を返す場合は、DS RRも返します
- 下位ゾーンへの委任がない場合:返すRRに対してRRSIG RRがあれば、それも返します
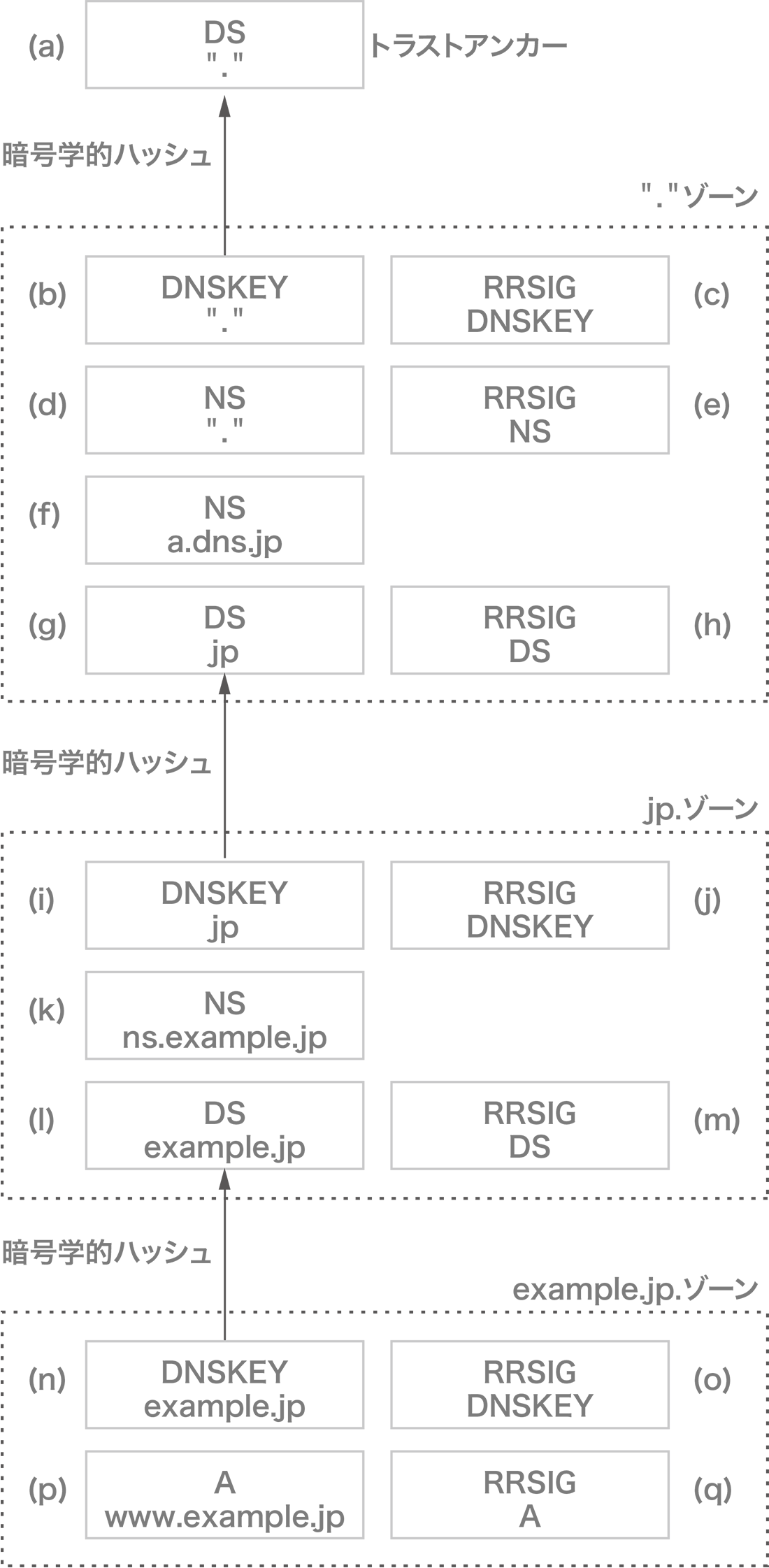
問い合わせ名最小化が相まった委任の検証は若干複雑なので、汎用的な解説ではなく、図-2を用いて、bowlineが"www. example.jp"のA RRをどのように解決するのか簡略的に説明します。なお、"."のDS RRは、トラストアンカーとして事前に提供されているとします。
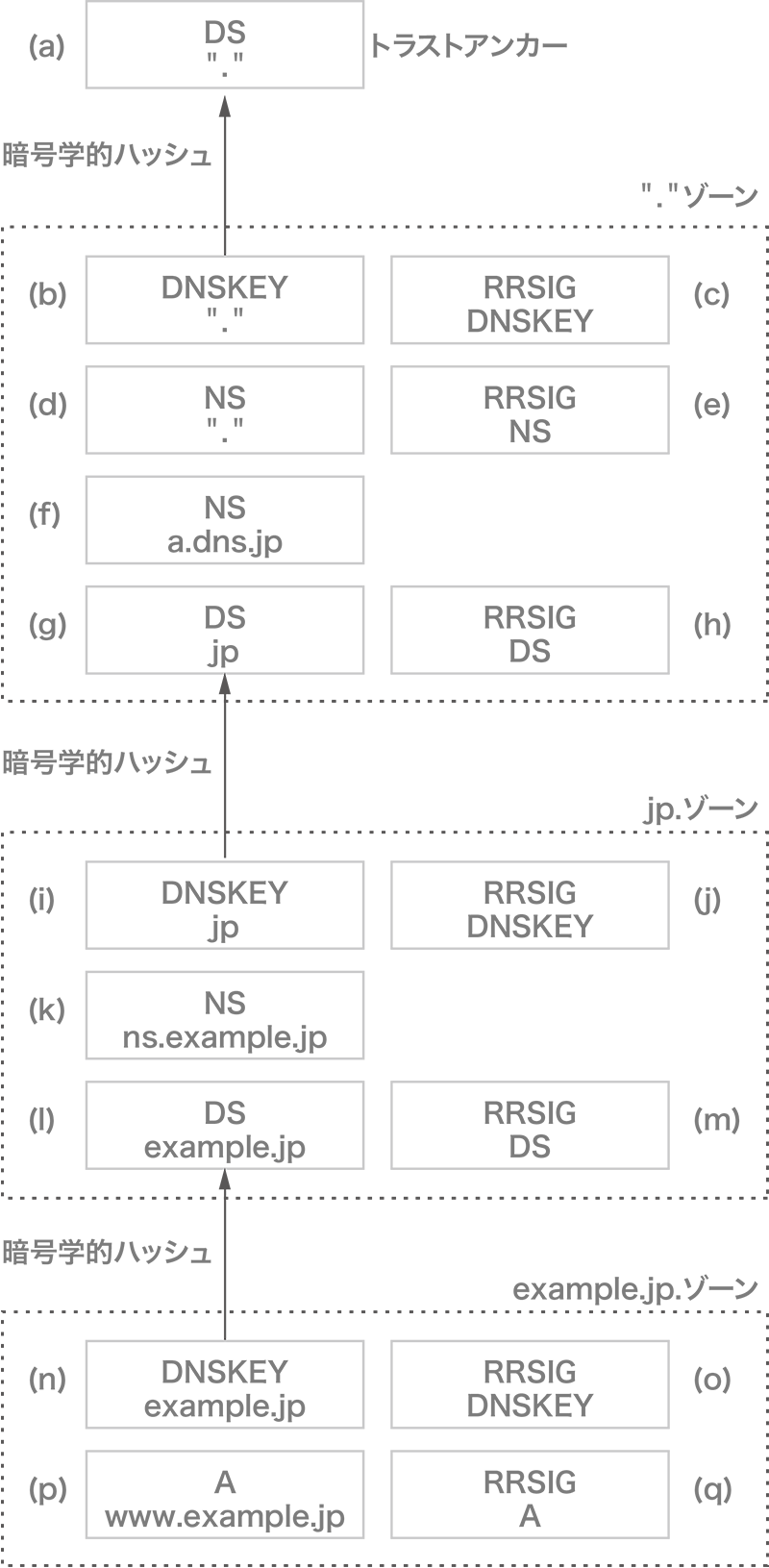
{kind=link}
{kind=link}
{kind=link}
{kind=link}
図-2 DNSSECの信頼の連鎖
- あらかじめ組み込まれている"."の権威サーバの候補に、"."のDNSKEY RR(b)を問い合わせ、トラストアンカーとして与えられた"."のハッシュ値(a)に合致するDNSKEY RRを選択します。これにはDNSKEY RR に対するRRSIG RR(c)も一緒に返されます。"."のDNSKEY RRに含まれている公開鍵で、RRSIG RRの中の署名を検証します。検証に成功すれば、"."のDNSKEY RRを信頼します
- あらかじめ組み込まれている"."の権威サーバの候補に、"."のNS RR(d)を問い合わせ、"."の権威サーバの一覧を入手します。NS RRに付随するRRSIG RR(e)の署名を"."の公開鍵で検証し、"."の権威サーバを信頼します(ルート・プライミング)
- "."の権威サーバに、"jp."のA RRを問い合わせます。"jp." の権威サーバを示すNS RR(f)やA/AAAA RRが返ってきますが、これに対応するRRSIG RRはありません。"."ゾーンで管理している情報ではないからです。"jp."のDNSKEY RRのハッシュ値が格納されたDS RR(g)も返されます。これには、RRSIG RR(h)が付いています。"."の公開鍵で、この署名を検証します。成功すれば、"." → "jp."の委任を信頼します
- "jp."の権威サーバに、"jp."のDNSKEY RR(i)を問い合わせ、"jp."のハッシュ値に合致するDNSKEYを取り出します。応答には、"jp."のDNSKEY RRに加えて、DNSKEY RRのRRSIG RR(j)も含まれています。DNSKEY RRの中の"jp."の公開鍵を使って、この署名の検証に成功すれば、"jp."のDNSKEY RRを信頼します
- "jp."の権威サーバに、"example.jp."のA RRを問い合わせます。"example.jp."の権威サーバを示すNS RR(k)やA/ AAAA RRが返ってきます。"example.jp."のDNSKEY RRのハッシュ値が格納されたDS RR(l)も返されます。これには、RRSIG RR(m)が付いています。"jp."の公開鍵で、この署名を検証します。成功すれば、"jp." → "example.jp."の委任を信頼します
- "example.jp."の権威サーバに、"example.jp."のDNSKEY RR(n)を問い合わせ、"example.jp."のハッシュ値に合致するDNSKEYを取り出します。これにはDNSKEYに対するRRSIG RR(o)が含まれています。"example.jp." のDNSKEYに含まれている公開鍵で、RRSIG RRの中の署名を検証します。検証に成功すれば、"example.jp."のDNSKEY RRを信頼します
- "example.jp."の権威サーバに、"www.example.jp."のA RR(p)を問い合わせると、RRSIG RR(q)も返ってきます。この署名を検証し、最終的な答えを信頼します
すべてのゾーンがDNSSECに対応しているわけではないので、認証の連鎖は途中で切れることがあります。bowlineでは、認証の連鎖が切れた場合、それ以降の反復検索ではDOフラグをオフにします。
2.4.1 親子同居問題
前述のように権威サーバは、下位ゾーンへの問い合わせに対して、検索が継続できるようにDS RRを返します。このように、DS RRを明示的に検索しなくても良い場合がほとんどです。しかしながら、認証の連鎖が切れてないにもかかわらず、DS RRが返らない場合があります。
それは、親のゾーンと子のゾーンが、同一の権威サーバで管理されているときです。例として、親のゾーンを"a."、子のゾーンを"b.a."、そしてこの2つのゾーンが同一の権威サーバで管理されているとします。
"a."の権威サーバに対して、"b.a."のA RRを検索したとしましょう。もし、親子が同居していなければ、"b.a."への委任情報、つまりNS RRやDS RRが返ります。しかし、この場合は親子が同居しており、DNSの要求にはどのゾーンを対象としているのかという情報がないため、最長マッチが働き"b.a."のゾーンが対象であると解釈されます。A RRがあればそれが、なければSOA RRが返り、DS RRは得られません。
この場合、実際には委任が存在するが、DS RRは返ってこなかったことを判定し、明示的にDS RRを問い合わせる必要があります。bowlineで採用している判定方法は以下のとおりです。
- "b.a."に対するA RRが存在すると、A RRに加えて、RRSIG RRが返る。RRSIG RR内の署名者名フィールドが"b.a."であれば親子が同居している
- "b.a."に対するA RRが存在しないと、SOA RRが返るので、そのドメイン名(RRのNAME部分)を取り出し、"b.a."であれば親子が同居している
2.4.2 スタブリゾルバが指定するDOフラグ
DOフラグは、スタブリゾルバがDNSSECに対応しているか、フルリゾルバに伝えるためにも使われます。このフラグに対して、フルリゾルバは以下のように振る舞います。
DOフラグがオフの場合、できる限りDNSSECを検証し、DNSSEC関連のRRを差し引いて返します。返答のAD (Authentic Data)フラグは立てません。
DOフラグがオンの場合、DNSSEC関連のRRもすべて返します。すべての検証が成功したら、返答のADフラグを立てます。途中からDNSSECの委任がなくなったら、返答のADフラグを立てません。どこかで検証に失敗したらSERVFAILを返します。
2.4.3 不在証明
DNSSECの話題としては、不在証明(NSEC/NSEC3 RR)もあります。技術的な内容は、この記事の範囲を超えるので、詳しくは「DNSフルリゾルバの実装へのDNSSECの組み込み - NSEC/NSEC3による否定応答の証明」(注4)をご覧ください。
2.5 キャッシュのデータ構造
キャッシュのデータ構造としては、探索木と優先度付きキューの両方の性質を持つPSQ(Priority Search Queue)を用いています。キーには要求(ドメイン名、RR型など)、優先順位にはTTL(Time To Live)、値には「反復検索の結果」を使います。すなわち、要求から「反復検索の結果」を効率よく検索可能であると共に、TTLに従ってキャッシュ・エントリを削除できます。
肯定応答は、DNSSECの署名がない場合、署名があっても検証していない場合、署名の検証に成功した場合に分けられます。キャッシュの保存期間は、基本的にRRのTTLの値です。ただしDNSSECの場合、RRSIG RRのTTLや、署名の有効期間によっても制限されます。
否定応答のNODATAとNXDOMAINは区別せずに、SOA RRから得られたTTLの値でキャッシュします。DNSSECで署名されているなら、NSEC/NSEC3 RRとRRSIG RRが得られます。これはNODATAあるいはNXDOMAINの不在証明の証拠なので、SOAと一緒にキャッシュします。
SERVFAIL、REFUSED、FORMERRの場合は、SOA RRが手に入りません。可能なら、肯定応答あるいはNODATAやNXDOMAINの否定応答を得たいので、次のIPアドレスの候補にフォールバックします。候補が尽きた場合には、同じ問い合わせが繰り返し使われる攻撃を防ぐために、この種の否定応答をキャッシュします。TTLには設定ファイルで指定された既定値を使用します。
応答にはランキングと呼ばれる優先順位があります。AA (Authoritative Answer)フラグがオフの応答から得たグルー情報は、権威付き(AAフラグがオン)の応答から得た情報よりも優先順位が低いです。ですので、前者のキャッシュ・エントリは後者が得られた時点で上書きされます。フルリゾルバはスタブリゾルバに対して、グルー情報がキャッシュに存在しても、それは返さず、権威付きの情報を得てから返します。
2.6 自由にコントロールできたか?
bowlineの目標の1つは、問題が発見されたときに自分たちで迅速に対応できるソフトウェアとすることでした。この節では、迅速に対応できた事例を挙げて、その証左とします。
まず脆弱性に関してですが、bowlineの開発中に運用部隊からドメイン圧縮回数に関する攻撃を説明されたり、外部情報としてKeyTrap攻撃を知ったりしました。これらの脆弱性はbowlineにも存在していたため、すぐに修正しました。
bowlineの試験運用で発見された問題としては、スタブリゾルバがトランスポートとしてQUIC及びHTTP/3を用いた場合、うまく通信できない場合があることが運用部隊から報告されました。その時点のHaskell quicライブラリでは、性能を向上するために、UDPの接続済みソケットを用いていました。接続済みソケットでは、途中のNATがポート番号を変更すると、パケットが届かなくなります。quicライブラリでは、マイグレーションの機能を備えており、QUICコネクションの確立後にポートが変更された場合は、新しい接続済みソケットを使って、コネクションを維持できます。
しかし、この現象を引き起こしたNATは、コネクションを確立させる最中にポートを変えていました。これに対処するために、性能は劣るものの、UDPの利用では一般的な未接続ソケットを使うように大幅な改良を加えました。
また、これはdugの話になるのですが、暗号化されたDNSサーバのいくつかは、TLSのセッション・チケットを複数返していました。この時点でのHaskell tlsライブラリは、セッション・チケットの数は1つであるという仮定に基づいて実装していました。暗号化されたDNSサーバの返すセッション・チケットから1つを選んで、セッションを再開すると、失敗する場合があることが分かりました。おそらくTLSの終端が複数あって、そのすべてのセッション・チケットを返しており、1つだけ選ぶと、受け取ったTLSの終端が期待しないセッション・チケットである場合があるのでしょう。そのため、すべてのセッション・チケットを利用できるように、tlsライブラリを改良しました。
2.7 おわりに
bowlineのサイトは、以下のとおりです。LinuxやmacOSのバイナリへのリンク、Docker Hubからの利用方法、そしてDebianでのインストール方法が記述されています。
https://iijlab.github.io/dnsext/bowline.html
bowlineのソースコードは、以下のURLが示すGitHubから入手できます。将来はHaskellのライブラリ登録サイトであるHackageに登録することで、Haskellのビルドシステムでも簡単にビルドできるようにする予定です。
https://github.com/iijlab/dnsext
bowlineプロジェクトの進捗は、以下で報告されています。
https://www.iijlab.net/projects/Underpinning/dns.html
最後になりましたが、この記事の草稿に対して、様々な意見をいただいたIIJの同僚の方々に感謝します。
- (注1)Internet Infrastructure Review(IIR)Vol.52、「HaskellによるQUICの実装」(https://www.iij.ad.jp/dev/report/iir/052/03.html)。
- (注2)IIJ Engineers Blog:「DNS検索コマンドdugの紹介」(https://eng-blog.iij.ad.jp/archives/27527)。
- (注3)IIJ Engineers Blog:「暗号化されたDNSサーバの探索」(https://eng-blog.iij.ad.jp/archives/31843)。
- (注4)IIJ Engineers Blog:「DNSフルリゾルバの実装へのDNSSECの組み込み - NSEC/NSEC3による否定応答の証明」(https://eng-blog.iij.ad.jp/archives/24512)。
執筆者プロフィール

山本 和彦( やまもと かずひこ)
IIJ 技術研究所 技術開発室 室長
2022年にIIJの正社員から契約社員となり、故郷の山口県に移住後、リモートワークで勤務。最近は、瀬戸内でサワラやアオリイカを追いかけている。
- 2. フォーカス・リサーチ(1)
DNSフルリゾルバbowlineの設計と実装
ページの終わりです