ページの先頭です
- ページ内移動用のリンクです
- ホーム
- IIJの技術
- セキュリティ・技術レポート
- Internet Infrastructure Review(IIR)
- Vol.25
- 3.クラウドコンピューティングテクノロジー
Internet Infrastructure Review(IIR)Vol.25
2014年11月25日
3.7 Lagopusにおける性能向上策
Lagopusでは、Intel DPDKを利用することで、性能ボトルネックの多くを解消しています。とりわけ、PMDとコア固定は大きく性能向上に貢献しています。また、Lagopusはスレッド構成が特徴的と言えます(図-3)。
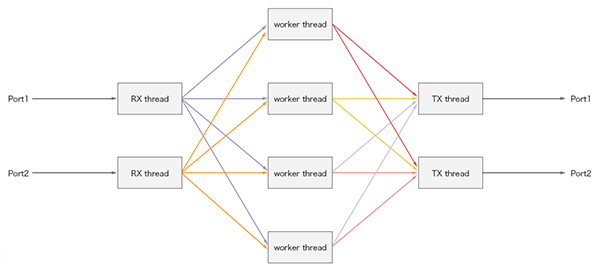
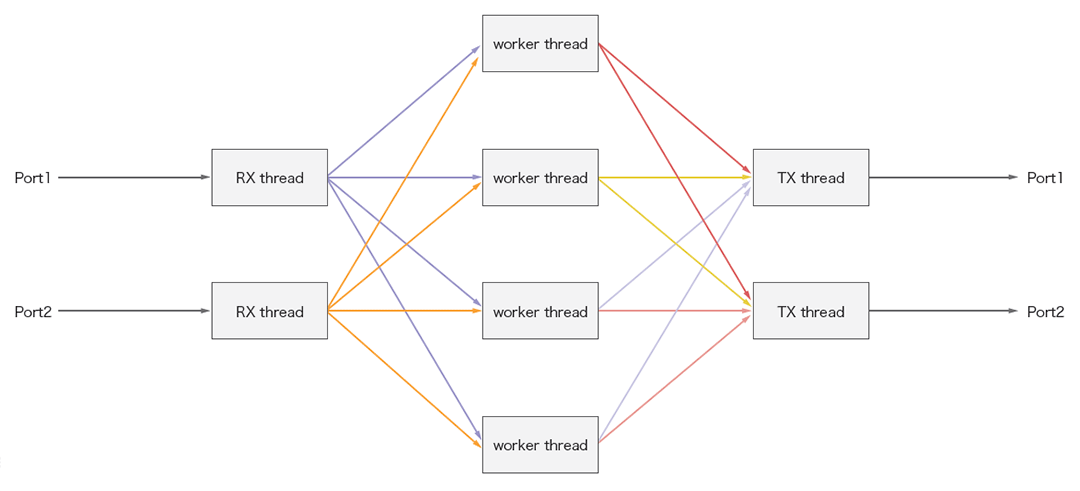
図-3 Lagopusのスレッド構成
Lagopusのデータプレーンは、パケットI/Oを担当するスレッドとOpenFlow処理を担当するスレッドが分かれています。更に、I/Oは受信(RX)と送信(TX)に、OpenFlow処理(worker)は複数のスレッドとなるよう起動時に指定が可能です。これらのスレッドは、それぞれ他の処理が割り当てられないよう別々のコア上で動くよう固定させることで、性能を確保しています。また、スレッド間の通信には、DPDKが提供しているロック処理不要のリングバッファを用いています。
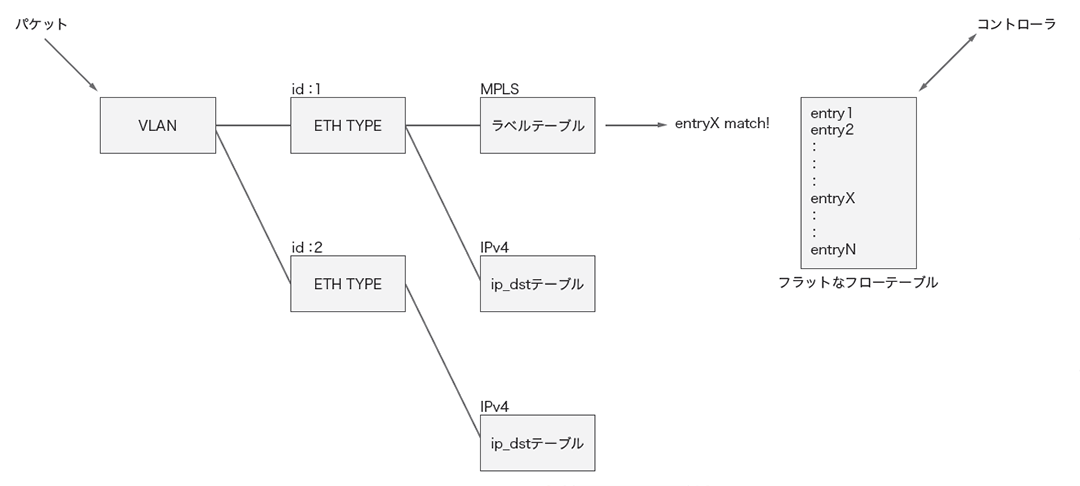
パケットI/Oの基盤部分は主にIntel DPDKを利用することでボトルネックを解消していますが、OpenFlow処理部分ではLagopus独自の性能向上策が見られます。Lagopusのフローテーブルの内部構造を図-4に示します。
{kind=link}
{kind=link}
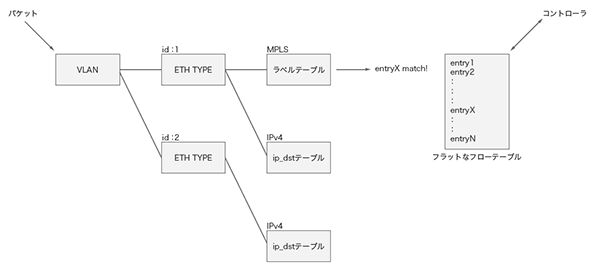
図-4 Lagopusのフローテーブルの内部構造
コントローラからの要求に応じてフローテーブル内容を出力する必要があるため、OpenFlow仕様を素直に表現したフラットなテーブルが用意されていますが、Lagopusではそれとは別にフロー探索に適した構造のテーブルが用意されています。この構造は現在のところ固定的で、どんなフローテーブルでも最適な探索ができるというものではありませんが、VLAN IDによる分岐、MPLSラベルによる分岐、IPv4宛先アドレスによる分岐、といったように、典型的に使われるであろうパケットヘッダに対して高速な探索を実現しています。また、一度探索したパケットの情報をキャッシュし、同じパケットを受信した際には、キャッシュからフローエントリ情報を取得し探索自体を省略するという、フローキャッシュの仕組みも実装されています。
以上の性能向上策の相乗効果により、Intel Xeonを用いた試験環境において、10万エントリのフローテーブルを投入した状態で、OpenFlowによるパケットヘッダ書き換えを伴うパケット転送にて、Lagopusは10GbEワイヤーレート(14.88Mfps)を達成することができました。そして現在Lagopusは、より複雑なフローエントリでの処理速度向上や、より多くのポートを同時に処理する際の性能の維持、更に、より高速なインタフェースへの対応を順次進めています。
ページの終わりです