STORY 03
検索エンジンとデータ処理
私たちの生活と検索
私たちがいつもPCやスマートフォンを使って何気なく行っている「検索」。その裏側では何が起こっているのか、どんなシステムが稼働しているのか、何も意識せずに検索し、その結果によって知識を得たり、行動したりしています。検索はもはや、服を着たり食事をしたりすることと同じくらい、生活に欠かせないものになっています。

米国メディア「Search Engine Land」の推計によれば、Googleの検索エンジンを使った2016年の検索回数は、少なくとも2兆回だったそうです。1999年は10億回だったため、17年で2000倍に増えている計算になります。
そして、世界中で行われる年間2兆回の検索アクションに対して、検索エンジンは膨大な数のWebサイトのなかから一瞬で情報を選び取り、適切なページを提案してくれます。
私たちは何も意識せずに検索していますが、よく考えてみると、この検索エンジンのリアクションは、実はすごいことなのではないでしょうか。
検索エンジンの変遷
では、検索エンジンがどのように発展してきたのかを紹介しましょう。
Webサイトそのものは、1980年代後半から作られるようになってきました。しかし、そもそもインターネットは、Webサイトを管理する人や組織が存在しないうえに(STORY 01参照)、その頃は検索という方法もありませんでした。
この問題に初めて対応したのがYahoo!です。
1994年に創業したYahoo!は、ディレクトリ型検索エンジンを開発し、Webサイトをカテゴリ分けして登録できるようにしました。いわば、大規模なリンク集を作り、整理することで、必要な情報が掲載されているWebサイトの検索を可能にしたのです。
その登録は、「サーファー」と呼ばれるスタッフが人力でWebサイトを収集するという方法で行われていました。また、WebサイトのオーナーがYahoo!のカテゴリを指定して登録を申請することもできました。
ある意味でインターネットの「電話帳」のようなものを作成していたといえるでしょう。
しかし、当然人力には限界があります。増え続けるWebサイトに対応しようと、1990年代中頃からロボット型検索エンジンの開発が始まりました。
1995年には、米国のDigital Equipment Corporation(DEC)がAltaVistaというロボット型検索エンジンを開発します。同じ頃、日本ではNTTが開発した検索エンジンのほか、早稲田大学や東京大学の学生が個人で作成したものも使われていました。
AltaVistaは、DECが開発した高性能のスーパーコンピューター(サーバ)の能力を示す目的もあり、単体のサーバを使用していました。それに対し、複数のサーバを使った並列分散処理による検索エンジンを実現したのがGoogleです。

並列分散処理のコンピューター
Googleが採用したサーバは、DECが使用したスーパーコンピュータの性能には及ばないものでしたが、その代わりに膨大な台数のサーバを用意し、処理を分け合うことで検索する仕組みを作りました。

Googleはある時期からサーバ保有台数を公表しなくなりましたが、2011年時点でも90万台以上のサーバを保有していたと言われています。これだけの数のサーバが役割分担し、協調することで、世界中のWebサイトから適切な検索結果を探し出して表示できるのです。
現在では、Yahoo!もGoogleの検索システムを利用するようになり、マイクロソフトのBingや中国のBaiduも並列分散処理による検索エンジンを使用しています。
私たちが何気なく検索をしている裏側では、膨大な数のサーバが稼働しているのです。
そして、膨大な数のサーバを用意するということは、そのサーバを格納する施設の確保も重要。さらに、サーバを動かすための電源の確保と、サーバが発する熱を冷却させるための温度管理が必要です。
IIJのデータセンターとは
このサーバを管理するのが「データセンター」。IIJでもさまざまな情報を管理するために、国内および海外に多数のデータセンターを保有しています。これらのデータセンターをケーブルでつなぎ、日本各地、世界各国からの接続に応えられるように対応しているのです。また、災害時などの停電に備え自家発電装置も完備するなど、安全で安定した接続を提供できるよう、サーバの管理を行っています。
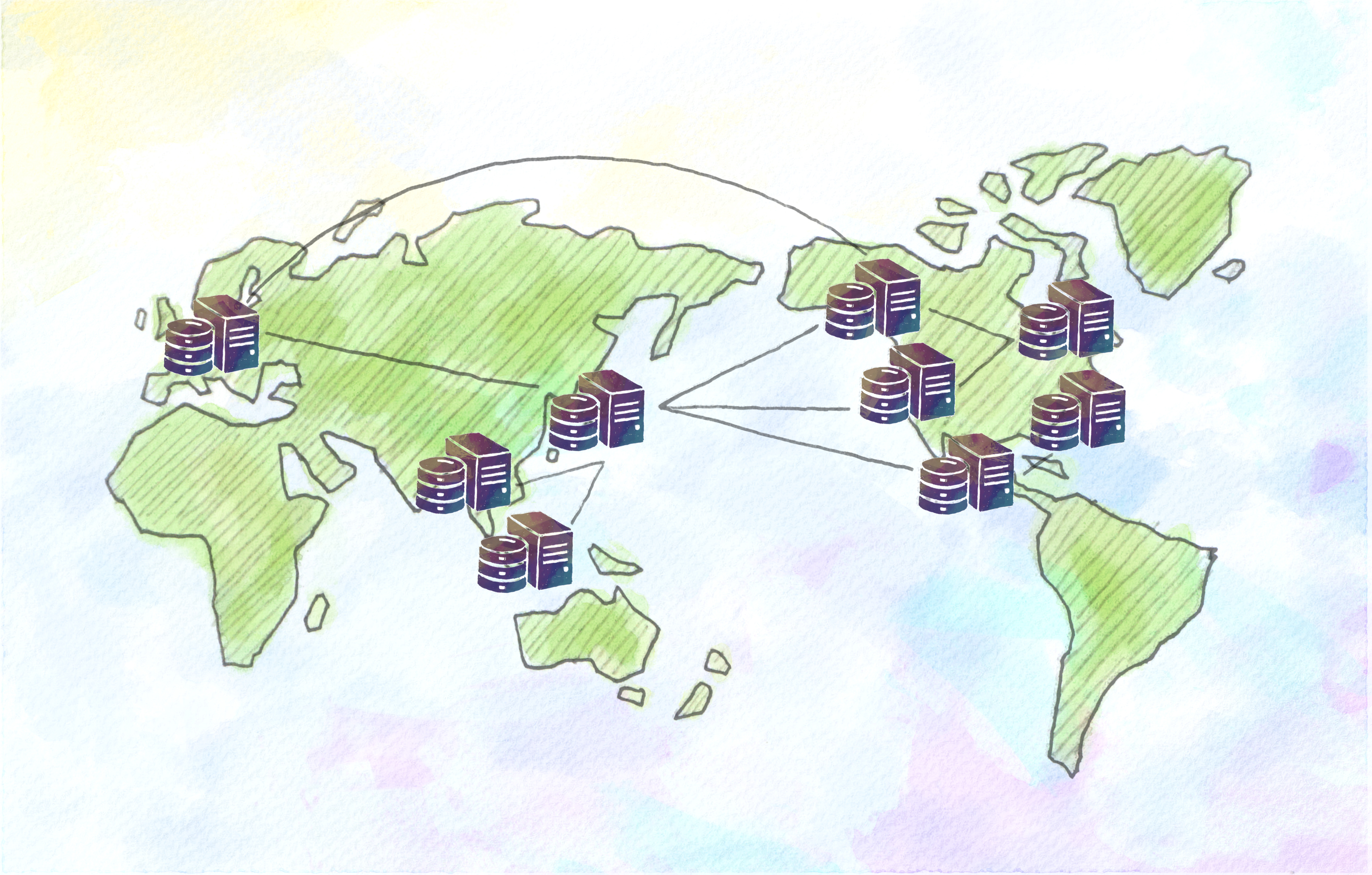
皆さんが何気なく見ているWebサイトのデータも、もしかしたらIIJのデータセンターに置かれているかもしれません。
本記事は2018年10月10日時点の情報を元に作成しています。
記事内のデータや組織名・役職などは作成時のものです。

- クラウド本部クラウドサービス2部
前橋 孝広(まえばし たかひろ)
- 主としてインターネットトラフィックに関する大量のデータを取り扱うエンジニア。そのためにたくさんのサーバを束ねる分散システムを駆使している。