ページの先頭です
- ページ内移動用のリンクです
- ホーム
- IIJの技術
- セキュリティ・技術レポート
- Internet Infrastructure Review(IIR)
- Vol.57
- 3. フォーカス・リサーチ(2)社内情報分析基盤「illumino」
Internet Infrastructure Review(IIR)Vol.57
2022年12月26日
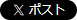
- 目次
3. フォーカス・リサーチ(2)
社内情報分析基盤「illumino」
3.1 はじめに
ITを活用した業務が日々拡大する中、情報量が加速度的に増えているのは多くの方が実感されていることでしょう。情報量に合わせて、管理するサーバやネットワーク機器とアプリケーションも増加していきます。それが、本来扱いたいデータ量以上に管理するべきデータ量が加速度的に増えていく要因となっています。
管理するべきデータ量が増えるに従って効率良くデータを扱うための工夫が重要になってきます。保存効率の向上、データの保全性、分析の容易性、分析の速度向上、データセキュリティの確保など、データを保存し管理する上で考慮するべき項目は多く、これまでの多くのプロジェクトでは保存・保全のみ、あるいは限定的に運用に必須な一部を利用するにとどまっていました。また、利用したいデータは構造化されたものだけでなく、テキストログのような構造化されていないものも多く分析の手間になっています。更には、アプリケーションアーキテクチャは重厚長大なものからマイクロサービスによる正規化と分散化が進んでおり、高度な分析手法が必要不可欠となってきました。
データ管理と高度な活用ができるシステムを共通基盤として利用できれば、本来取り組むべきサービスやシステムの価値向上に注力できるだけでなく、これまで実現できなかったデータ活用による新たな価値創出につながるはずです。これを実現するシステムが「情報分析基盤『illumino』(イルミノ)」です。
本稿では、「情報分析基盤『illumino』」の機能と、これまで解決した課題と方法について紹介します。
3.2 illuminoの紹介
3.2.1 社内情報分析基盤「illumino」について
課題
IIJでは多くのシステムが稼働しており、その数は年々増加し規模も大きくなっています。各システムで生成されるデータの管理は、これまではそれぞれのシステムごとに必要十分な施策がなされていました。プロジェクトによっては高度なデータ分析を実装し進化しているものがある一方で、コストや工数の課題から「必要十分」なままで運用されているサービスも多くあります。十分に活用されていないデータは、そのシステムの潜在的価値だけでなく、会社全体としての価値を秘めている可能性もあります。
近年はデータを活用するソリューションの進化が急速に進み、「大量のデータを効率的に管理」し「高度な分析」を実現することが以前に比べて容易となっていますが、各システムでそれぞれに導入する場合は、必要になるコストと管理・分析のノウハウが分散するという課題が生じていました。
解決方法
そこでこれらの課題を解決するために、データの管理と分析を「低コスト」で「容易」に導入できるような共通プラットフォームを構築しました。それが「情報分析基盤『illumino』」です。データ分析に必要となる「データ保存」と「分析ツール」、それらに必要な「システムの運用」と「専任のエンジニアによる導入支援」をサービスとして提供するソリューションです。
このソリューションは社内のプロジェクトであれば誰でも利用できます。サービスとして提供されているため、利用申請を行えば最短で即日利用することができます。
改めてメリットを整理します。
- データ保存
大容量データを安全に低コストで保存することができます。 - 分析ツール
高度なツールが利用できます。 - システム運用
利用者側プロジェクトで負担する必要がありません。 - 導入支援
専任のエンジニア/データサイエンティストによる支援があります。
現在は多くの社内システムが「illumino」を利用しており、データ分析と活用が進んできました。
3.2.2 データ分析とは
ITOAとは
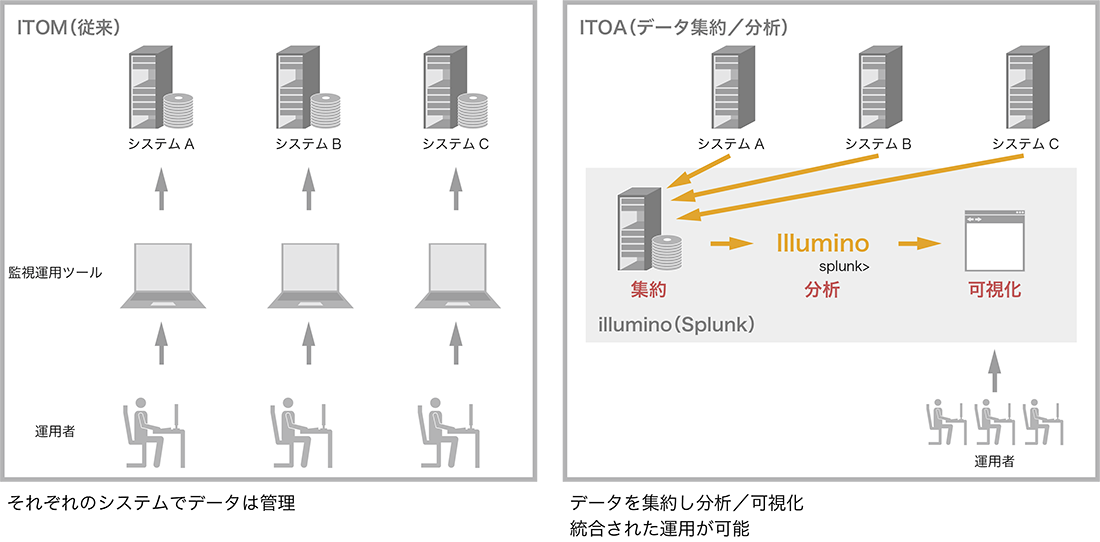
日々の活動でITへの依存度が高まっていることは多くの方が実感されているでしょう。依存度が高まるにつれて、システムの安定稼働は高いレベルで求められるようになりました。一方でシステムの数は増加し、それらで構成するサービスは複雑化・大型化しています。システムやサービスが進化し続ける中、IT運用も当然変わらなければなりません。求められる高い安定稼働を実現するためには、従来のIT運用 ITOM(IT Operation Management)から、ITOA(IT Operation Analytics)への変革が求められています。
仮に「あるサービスで障害が発生した」としましょう。従来のIT 運用では、それぞれのシステムでそれぞれに管理されたデータを調査し、関連する部門に調査協力を依頼、以降は解決するまでこの繰り返し、というシーンがしばしばありました。サービスの複雑化・大型化により、利用者が認知もしくは監視ツールなどが検知した障害発生システムが直接の原因ではないケースが当然多くなり、更には関連するシステム=被疑となるシステムは増えることになります。
ITOAとは、その名のとおりITの運用を「分析(Analytics)」することによって解決する手段です。大量のデータに対して「効率良く集約」「高速検索」「高度な分析ロジック」を実現することで、障害発生時には検知したエラーから関連するデータ(ログ)を自動的に検出し、迅速に原因にたどり着けるようになります。更には様々なデータ分析を試みることで、潜在課題や新たなニーズを予測することもできるでしょう。
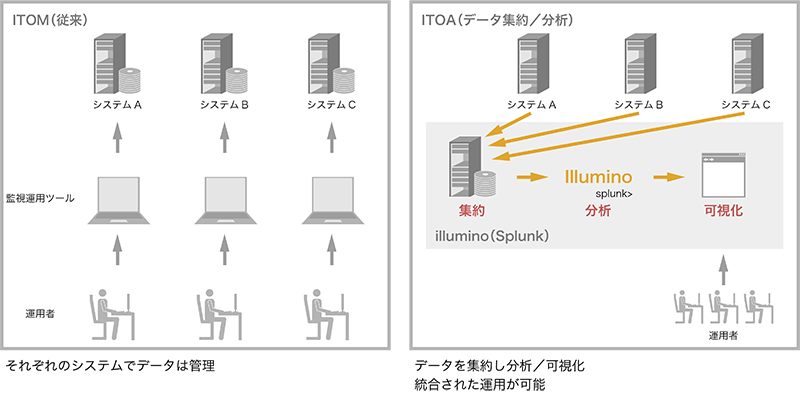
図-1 ITOAの運用イメージ
Splunk概要
ITOAを実現するためには「データ集約」「高速検索」「高度な分析」が重要となります。多くのITOA関連ソリューションがリリースされていますが、IIJではSplunk社の「Splunk Enterprise」を採用しました。
Splunk Enterpriseを採用した理由は以下のとおりです。
- 社内での利用実績があったこと
一部のプロジェクトで利用実績があり、高いレベルのスキルセットがあったこと - エンタープライズグレードの利用実績
Splunkはワールドワイドに大規模・大容量での利用実績があり、IIJ共通プラットフォームとしての利用を想定した場合でも十分なパフォーマンスが得られること - システム構成の柔軟性
データー投入側システムとの接続性やセキュリティを考慮し、社内IaaSへの構築が望まれていたこと。一方でSplunk Cloud PlatformやSplunk ObservabilityなどSaaS利用も想定し、柔軟な連携ができること
データ集約
一言でデータと言ってもその形式は様々で、求める結果を得るためにはいくつかのプロセスを経なければならないことがほとんどです。一般的なデータ活用アプリケーションは、求める結果を想定し扱いやすいように事前に構造化する必要がありました。
データ活用・分析を進めていくと、その過程で新たな課題に気がついたり別のアプローチが必要になるといったシーンはよくあることです。このようなケースでは「事前に構造化したデータが逆に扱いにくい」あるいは「そもそも構造が適さない=不十分なデータとなっている」ことがあり、ときには改めて構造化からやり直さなければなりません。
更に過去に遡って分析を行う必要に迫られたときを想定してみましょう。元となるデータは保存効率のためにアーカイブされていることが多く、容易に扱える状態とは限りません。仮に扱える状態だったとしてもその処理はデータ量に比例して難易度が高くなるでしょう。
データを前処理し構造化することでデータ量を減らしたり検索速度を上げることができるので、特定の目的であれば十分にメリットがあります。しかしながら、前処理にかかる手間を省けて、データ量に対するストレージコストが抑えられ、なおかつ検索速度を高速にできるとなればどうでしょうか。
Splunkは、データを加工せずに非構造のまま保存し高速に検索できることが大きなメリットです。利用者はデータの型を問わず未加工のまま投入します。投入する仕組みは、Splunk専用の転送ツール(forwarder)で容易に設定できたり、fluentdなどの一般的な転送ツールと連携したり、多くの手段が用意されています。
データ活用の要件を詰める前に、まずは保存管理を目的としてilluminoにデータを投入するだけでも十分なメリットが得られるでしょう。多くのデータが集まれば、それらを組み合わせて分析することで新たな価値が見出せる=データを集約すること自体に価値が生まれる、と言っても過言ではないでしょう。
高速検索 インフラでの工夫
illumino(splunk)に取り込まれたデータは高速に検索できるように様々な工夫がなされます。無秩序=ランダムに保存したデータでは、潤沢に高速なストレージとCPU・メモリがあっても検索時間はデータ量に比例しますし、サーバ費用も大きくなってしまいます。
重要なキーワードは「時系列」です。多くのデータは発生した時間が記録されています。illumino(splunk)では、常に時系列順にデータがソートされます。
必要とされる検索は、比較的直近のデータが対象となるケースが多いことが統計上、分かっています。直近のデータは高速なSSDストレージに、時間が経過したデータは単価の安いオブジェクトストレージに保存されます。オブジェクトストレージに保存されたデータが検索の対象になっても、illumino(splunk)ではシームレスに結果を返すので、利用者がストレージライフサイクルを意識する必要はありません。オブジェクトストレージに配置されたデータの検索はやや低速になりますが、illumino運営チームでオブジェクトストレージの稼働状況を監視し最適な配置となるようなチューニングを実施しています。
検索用のサーバに潤沢なCPUとメモリを搭載した高性能サーバを並列に構築しています。構造化されていないデータを処理するために、検索内容によっては多くのCPUとメモリでの計算能力が必要になることもありますが、十分に実用に耐えるレスポンスを維持しています。単一のシステム(サービス)ではコストがかかるため準備できるサーバの性能には限界がありますが、共通インフラとすることでコストを按分することができるので、潤沢なインフラを利用することができます。Splunkの強みと、共通インフラ化によるコストメリットを活かし、利用者ごとに負担するべきコストを抑えつつ高速検索を実現するための工夫です。
高速検索 Splunkの高度な利用
ある程度のデータ量と検索内容であれば、特別な工夫をせずともSplunk製品とillumino環境の強力な検索性能で十分なレスポンスは実現できています。しかしながら、基盤インフラなどの数千~数万台規模で時間当たりのデータ量が膨大なものを対象としたり、複雑な検索条件での処理が必要になると、効率的とは言えないケースも出てきます。
このようなケースでは、Splunkに取り込んだデータを取り込み時または任意のタイミングで、一部を構造化することもできます。この場合も未加工のオリジナルデータを保存するので、分析の柔軟性が失われることはありません。構造化データを保持するために追加でストレージを消費しますが、オリジナルデータへの参照ポインタのような方式を採るため比較的少ないストレージ消費増で実現できます。
構造化のようなデータの前処理は、従来の方式ではデータ管理者のような特権ユーザによる対応がしばしば必要になりますが、Splunkでは利用者自身で設定できることも大きなメリットです。要件分析と並行して利用者自身でチャレンジできると、より早く目的のアウトプットにたどり着くことができるのは明らかでしょう。
このようなSplunkの機能を活用するにはある程度Splunkに関するスキルが必要です。そこでIIJでは専任のチームによるサポートを確立し利用プロジェクトの学習コストを抑える工夫もなされています。
可視化
大容量のデータを高速に検索できるだけでなく、その結果を利用者が意味のあるデータとして認識できる表現にすることも重要です。データの「可視化」です。
抽出したデータは、表(テーブル)のような形式でまずは出力されることが多いでしょう。Splunkでは、テーブルデータを様々な種類のグラフなどに容易に変換できる「視覚エフェクト」が用意されています。
シンプルな折れ線グラフや棒グラフはもちろん、数十種類のエフェクトが容易なGUI操作で利用できます。可視化した検索は定期的に実行してレポートとして作成したり、ダッシュボードを作成して1画面で表現することもできます。
分析言語
データの検索と分析はSplunk独自のシンプルで強力な言語「SPL:Search Processing Language」を利用します。データソースを指定して、任意の条件でフィルターをかけるところはRDBのSQLに似ていますが、強力なのはその後に続く「分析」機能です。SPLは「|」(パイプ)でコマンドをつなげて、いわゆるワンライナーとして記述するプログラム言語です。検索により抽出されたデータを「|」でコマンドに渡すだけで分析ができます。
例えば、時系列で件数を数えたい場合は、検索結果の後に「| timechart count」と書くだけです。Webサーバのログで時系列ごとにHTTPステータスごとの件数を出したい場合は「| timechart count by status」とします。直感的でシンプルなので誰でもすぐに使えるようになります。
3.3 課題と解決策
ここまで、illuminoプロジェクトとその内部システムのSplunkについて紹介してきました。この節では、実際にilluminoを利用している事例について、課題と解決方法を紹介します。
3.3.1 大量データの保存・管理と可視化
課題
IIJ社内では多くのシステムが稼働しており、それらのネットワークとサーバインフラは特別な理由がない限り共通のシステムを利用しています。いわゆる「社内IaaS」です。システムは数千台のサーバとネットワーク機器で構成され、これまでは各種ログとメトリック情報を専用のシステムで集約していました。
このインフラの歴史は比較的古く、ログとメトリック情報はシンプルな可視化ツールで参照はできるものの、更なる活用や分析は実現できていませんでした。インフラ規模が大きいためデータ量も多く、保存管理のためのコスト改善も課題となっていました。
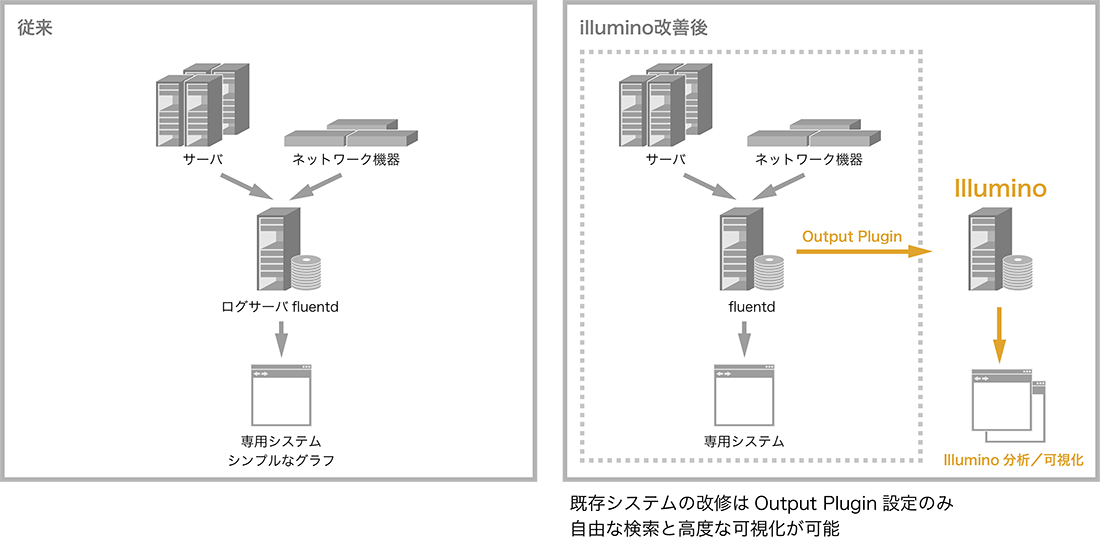
データ保存・管理の改善
初めのステップとして、illuminoにこれらのデータを投入することから着手しました。これまでもfluentdなどでデータの集約は行っていました。illuminoに投入するデータは構造化が不要でfluentdから直接投入ができるため、転送先にilluminoを追加設定するだけで対応することができます。容易な設定追加のみでコスト改善が実現できました。
データ活用
従来のシステムでは、データを参照するには専用のシステムのWebページから規定の形式でグラフ化されたデータを見るか、担当部門にデータ抽出を依頼する必要がありました。
illuminoに登録されたデータは、権限があるユーザであれば自身で検索ができるようになっています。従来システムと同等のグラフは数行のSPLで参照できますし、オリジナルデータをそのまま保存しているので期間や分類など自由に設定して参照できるようになりました。
社内IaaSを利用するシステムは多種多様で、ログやメトリックデータの分析の重要性もそれぞれ違ってきます。データの変化に厳格なものもあれば比較的寛容なものもあり、厳格なものの中でも、CPU負荷が重要な指標になるシステムもあれば、ディスクのIO負荷状況が重要となるシステムもあります。シンプルな分析と可視化は共通のレポートやダッシュボードで提供しつつ、各システムで独自に重要な指標に着目したレポートやダッシュボードを作成し、それぞれの運用に合わせた分析と可視化を実現しているプロジェクトもあります。
更に、社内IaaSを利用している各システム側のログを投入し、それらのデータを分析・可視化したものに社内IaaSのデータを連携させ、各システムとインフラ利用状況の関連を可視化している例もあります。システムの利用とインフラ負荷の状況を統合して可視化することで運用精度が向上しています。
図-2 illumio導入によるデータ活用イメージ
3.3.2 システム/サービス間のデータ共用
課題
IIJのサービスをご利用いただいているお客様や社内システムを利用しているチームでは、いくつかのシステムを組み合わせて利用しているケースが多くあります。サーバとネットワークのようなパーツを組み合わせたり、業務アプリとセキュリティサービスのような組み合わせもあります。システムの運用はそれぞれの担当チームで行っているため、管理されているデータの連携はできていませんでした。障害が発生したり利用状況分析などで調査・分析を行う場合、利用しているシステムのデータを横断的に調べる必要がありますが、担当チームの連携に手間と時間がかかっていました。
データ集約と共用
illuminoは、共有システムであることと非構造化データを扱えることから、様々なシステムからデータを集約することができます。システム単体でのデータ分析だけでも十分なメリットはありますが、いくつかのシステムやサービスを連携して利用している場合は更に大きなメリットがあります。
例えば、業務アプリケーションとセキュリティサービスを組み合わせて利用している場合を考えてみましょう。業務アプリケーションの画面にエラーが表示されたとします。利用者は、表示されたエラー内容、アカウント名、発生時間などを報告してくれたとします。運用担当者は報告内容を元に、ログなどを確認して原因の特定を始めます。業務アプリケーションに原因があった場合は比較的シンプルです。ログなどから原因を示すエラーを見つけられれば、次の対応ステップに進むことができるでしょう。

図-3 統合サービス監視ダッシュボードのイメージ
原因が業務アプリケーションにあるのではなくセキュリティサービスにあった場合はどうなるでしょう。業務アプリケーションのログにはエラーは出ていたとしてもセキュリティサービスに原因があることを示唆するにとどまったり、そもそもエラーが出ていないケースもあるかもしれません。このような場合、次のステップはセキュリティサービス側の調査を行うことになります。各担当チームの連携はスムーズに行われるように業務設計されていますが、チーム間の連携がシステム化されていない場合はある程度の時間と手間がかかってしまいます。
illuminoにデータが集約されることにより、データを関連付けて検索・分析を行うことができます。前述の例の場合、調査の起点となる業務アプリケーションの調査と連携して、セキュリティサービスの調査を行うことができるようになります。
業務設計に合わせて複数システムを連携させた運用ツールを作成することで、調査にかかる時間と手間を大幅に削減することができます。
データのセキュリティ
データの集約と共用は大きなメリットがある一方で、データセキュリティは慎重に考慮せねばなりません。有用なデータにはしばしばセンシティブなデータが含まれます。それぞれのシステムでデータセキュリティを精査し、共有システムに投入するデータの内容と、それを公開し共用する範囲を管理することが重要です。
illuminoではセキュアな社内専用インフラ基盤にシステムを構成することによるデータ保護と、データの参照権限を詳細に設定することで、高度なデータセキュリティを実現しています。
権限管理の運用は高いレベルの品質が求められるため、負荷が高くコストもかかりますが、ロールベースでの権限管理のため利用者のニーズに合わせた柔軟な対応とスマートな運用ができています。
3.3.3 機械学習
課題
大量のデータを活用価値のあるデータに変換する手法の1つに機械学習があります。昨今では機械学習のノウハウは比較的容易に入手できるようになり、具体的な事例やソリューションも提供されているため、IIJ社内でもニーズが高まっています。しかしながら、大量データを処理するインフラの準備やデータ操作にかかる手間のハードルは高く、ニーズの高まりに十分に対応できてはいませんでした。
機械学習とは
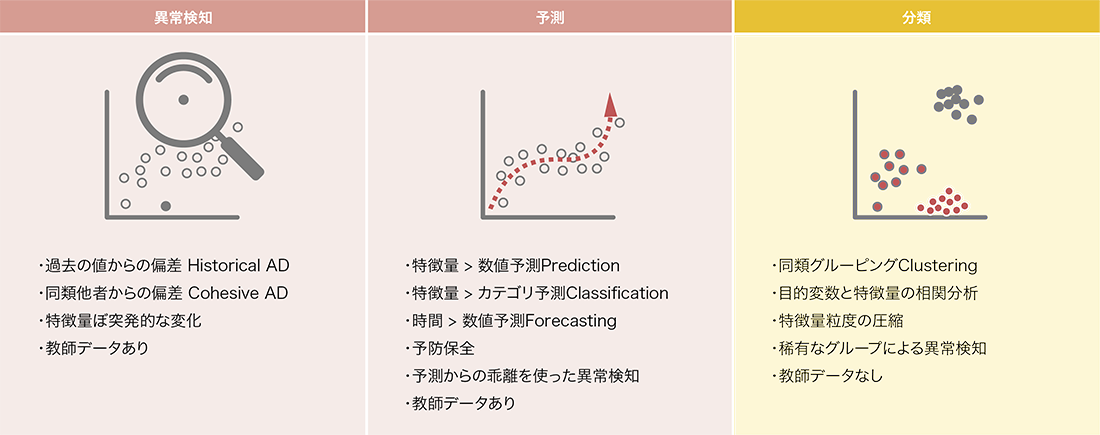
「機械学習」とは、オリジナルデータからパターンを抽出し予測や分析を行う手法です。大量かつ複雑なデータを統計学的に検証された手法で分析することで、運用者自身で仮説設定・設計・実装をするルールベースでは難しかったパターンを抽出することができます。抽出したパターンを利用する主なユースケースには異常検知や予測、分類があります。
Splunkの大きなメリットの1つに機械学習との高い親和性があります。大量のデータを集約し高速に検索や分析ができるシステムだからこそ実現できます(図-4)。
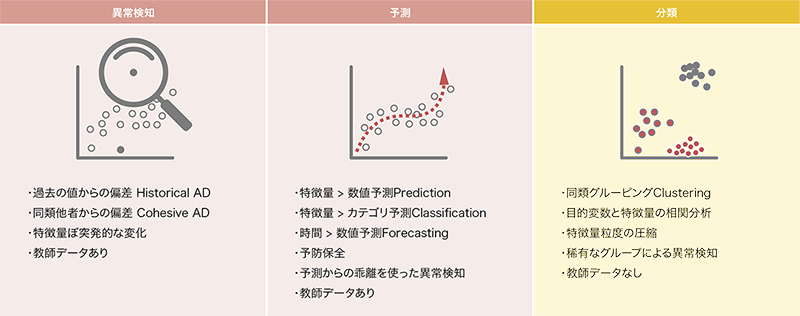
図-4 機械学習による異常検知・予測・分類
機械学習の基本
機械学習のロジック自体はillumino(Splunk)独自の機能ではありません。実際に、Splunkで提供されている機械学習の主要なロジックは、pythonで実装されているオープンソースで実装されています。
極論すればpythonの基礎と機械学習OSSの知識があれば、illuminoがなくても機械学習の実現はできます。しかしながら、illumino(Splunk)を介することで、様々なメリットがあります。
illuminoで機械学習を利用できるメリット
機械学習を行うためには、まずは学習元となるデータを用意する必要があります。学習元データはデータの精度が検出品質に大きく関わってきます。
機械学習に適した学習元データを作成するステップには次のようなものがあります。
- データ抽出=大量のオリジナルデータから適切な学習元データを抽出
- クレンジング=データに混入するノイズや欠損などを修正・補完
- データ変換=正規化によりデータのスケールを合わせる
これらの前処理を、illumino(Splunk)では検索言語SPLで行います。どのように抽出・修正・補完・正規化するかの中身は利用者が判断する必要はありますが、判断後の処理はSPLで容易に記述することができます。作成した学習元データは、illumino の機能でグラフ化などの可視化ができるので精度の評価にも役立ちます。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
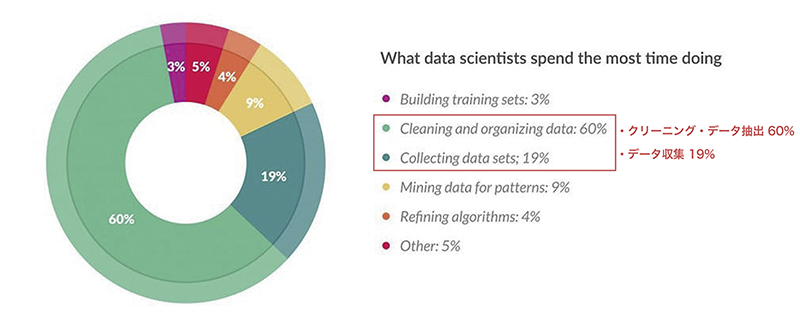
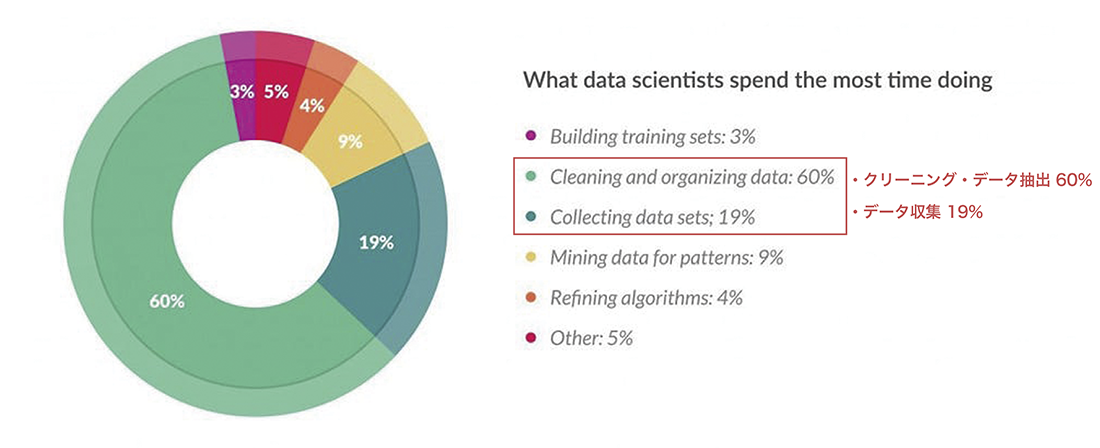
図-5 機機械学習における各処理に占める時間*1
学習元データを作成した後は、機械学習ロジックに投入し「モデル化」を行います。この機械学習ロジックへの投入もSPLで記述します。SPLを記述する方法だけでなく、GUIからもロジック投入と精度評価を行うこともできます。GUIでの精度評価は、学習元データの分布をグラフで表示したり、閾値パラメータをスライドバーで変更して変化を見るなど、視覚的に確認することができます。これらの前処理は、機械学習の工程のうち約8割を占めるというデータがあります(図-5)。illuminoを利用すると前処理の手間を大幅に削減できます。
モデルを作成した後は、検証対象データに対しての評価を行います。評価もSPLで記述することができ、結果を監視アラートに発報したり、グラフなどに容易に可視化することができます。機械学習のすべてのステップをilluminoで実現できるため導入の敷居が大幅に下がりました。
機械学習を利用した例
IIJ社内で利用している例として「異常トラフィック検出」を紹介します。
あるシステムでは、正常性確認の1つとしてネットワークトラフィックを監視しています。従来は特定の上限下限値を固定値として監視設定するにとどまっていました。このシステムはビジネスユーザ向けのため、平日日中と夜間、休日でトラフィックの傾向が大きく違うことが分かっています。全断に至るような障害ではないものの、通常のトラフィックとは明らかに異なる傾向が観測されることがあり、一部機器の不良や外部要因による異常で特定のユーザに障害が起きているケースが懸念されていました。特に比較的低トラフィックとなる夜間や休日など、固定の閾値設定では検出が困難でした。
このようなケースに対応するために、機械学習により過去のデータを分析し確率密度分布(DensityFunction)を利用した閾値設定を実装しました。正常に稼働している過去のデータを用意し機械学習で処理をすることで、統計学的視点で「稀である上下限値」を算出することができます。「稀である上下限値」を閾値にしてトラフィックデータを監視し、閾値超えを検出した際は詳細調査を行うことで、これまで認知できていなかった事象を把握できるようになります。
幸いなことに、機械学習による監視を実装してから障害は発生していませんが、仮に障害が発生した場合は正確かつ早期に対応ができるようになりました。
3.4 まとめ
本稿ではIIJ社内でのデータ活用の課題とilluminoプロジェクトによる解決、実際の活用事例と効果を紹介しました。
データ活用のニーズは今後も高まることは確実です。illumino プロジェクトでは、より多くのシステム・サービスでの利用を推進し、サービスの向上に努めてまいります。
- *1Cleaning "Big Data: Most Time-Consuming, Least Enjoyable Data Science Task, Survey Says" Forbs Mar 23,2016(https://www.forbes.com/sites/gilpress/2016/03/23/data-preparation-most-time-consuming-least-enjoyable-data-science-task-survey-says/?sh=dd178886f637
 )。
)。
執筆者プロフィール
工藤 隆久 (くどう たかひさ)
IIJ ネットワーク本部 プラットフォーム開発部 アナリティクス&マネジメントシステム開発課。
2008年にIIJに入社。illuminoプロジェクトの企画・運営に従事。illuminoシステム管理者。Splunkの社内エバンジェリストとして活動。
- 3. フォーカス・リサーチ(2) 社内情報分析基盤「illumino」
ページの終わりです