ページの先頭です
- ページ内移動用のリンクです
Internet Infrastructure Review(IIR)Vol.33
2016年12月15日
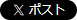
- 目次
3.7 WikipediaからNEコーパスを生成する
NLTKの話に戻ります。NLTKのNERの概要は"入門自然言語処理"(原書:"Natural Language Processing with Python")の第7章「テキストからの情報抽出」で解説されていますが、その実装はNLTK Corpora(※6)の1番目にリストされている"ACENamed Entity Chunker(Maximum entropy)"です。
この「最大エントロピー」と呼ばれる機械学習モデル(同書の「6.6最大エントロピー分類器」に解説があります)は、固有表現タグを注釈したNEコーパスを使用します。単語に「人名」や「組織名」といった固有表現タグを付与するNEコーパスの作成は人間が介在せざるを得ない非常に手間のかかる作業で、故に無料配布されているNEコーパスはほとんどないそうです。実際、NLTKの場合もAutomatic Content Extraction(ACE)が作成したコーパスを使って学習したチャンカーのみをpickleファイルとして配布しています。コーパスそのものは含まれていません。
このNEコーパスをWikipediaのページデータを使って機械的に生成しようという試みがあります。論文"Transforming Wikipedia into Named Entity Training Data(※7)"で は 、固有表現の注釈付きのコーパスを作成するために、Wikipediaの利用を提案しています。
{kind=link}
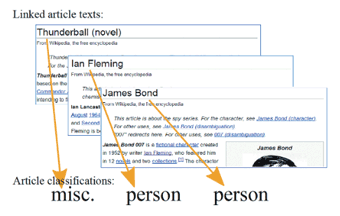
図-4 Deriving training sentences from Wikipedia text
Wikipediaの記事の中で記載された用語や名前は、多くの場合、適切な他の記事にリンクされています。そのような記事間のリンクを固有表現の注釈に変換することがこの論文の基本的なアイデアです。例えば「イアン・フレミング」の小説「サンダーボール」において「ジェームズ・ボンド」というキャラクターについて紹介する文章は、各々の固有表現について相互にリンクが張られていることが期待できます。「イアン・フレミング」の記事は、その表現が人物であることを示してくれるでしょうし、「サンダーボール作戦」の記事から、それが小説であることが分かります。このようにリンクを辿ると元の文章には自動的に注釈を付けることができるわけです(図-4)。
論文ではWikipediaからNERをトレーニングするための何百万もの文章を抽出して、巨大なコーパスを形成することができると述べています。そのプロセスとして次の4つのステップを掲げています。
- すべての記事をエンティティクラスに分類する
- Wikipediaの記事から文章を取り出す
- リンクターゲットに応じて固有表現をラベル付けする
- コーパスに収録すべき文章を選択する
この手順を使って、論文では標準的なCONLLカテゴリのエンティティクラス(LOC、ORG、PER、MISC)に基づくNEコーパスの生成を試みています。
現在では英語版は500万以上、日本語版でも100万を超える記事を収蔵するWikipediaを対象にこの手順を実行するのは明らかにビッグデータ処理になります。特に論文が記事の分類のために示すブートストラッピング、すなわち一部は人手でクラスを判別する方法はコーパスを完全に機械的に生成する上での困難な課題でしょう。
- (※6)NLTK Corpora(http://www.nltk.org/nltk_data/
 )。
)。 - (※7)Transforming Wikipedia into Named Entity Training Data(https://www.aclweb.org/anthology/U/U08/U08-1016.pdf
 )。
)。
ページの終わりです