ページの先頭です
- ページ内移動用のリンクです
- ホーム
- IIJの技術
- セキュリティ・技術レポート
- Internet Infrastructure Review(IIR)
- Vol.26
- 2.クラウドコンピューティングテクノロジー
Internet Infrastructure Review(IIR)Vol.26
2015年2月25日
- 目次
2.2 大規模インフラの基盤技術の取り組み
2.2.1 基盤開発
クラウド基盤の考慮点
我々はクラウドサービス事業者ですので、ハードウェアに対しては「大量の機器をいかに効率的に運用できるか」ということを常に意識しています。ただ、単純に効率化を突き詰めるならハードウェアを均一化することが理想ですが、IIJ GIOのように多岐に渡るサービスラインナップの網羅と費用対効果を考慮すると現実的にはまだ難しく、現時点では可能な限りの均一化を目指しています。
例えば、Web系企業やソーシャルアプリケーションプロバイダをターゲットとするパブリッククラウド系のIIJ GIOホスティングパッケージサービスの基盤では、価格競争の激しいパブリッククラウド領域で戦うため、過剰な冗長構成を排除した割り切ったハードウェア構成とOSSを組み合わせて提供しています。一方、エンタープライズ分野をターゲットとするプライベートクラウド系のIIJ GIOコンポーネントサービスの基盤では、オンプレミスの拡張リソース、もしくはオンプレミスからの移行先の受け皿として、オンプレミス同等以上のハードウェアの冗長性を備えています。また、お客様が連携、もしくは持ち込む既存の商用製品との組み合わせが動作保証されるクラウド基盤が求められるため、それに合わせた商用製品を組み合わせて提供しています。何より、サービス基盤の安定化を図るためには、技術リスクの分散が不可欠です。ファームウェアやドライバの不具合リスクをゼロにすることは不可能ですから、何か不具合が発生した場合の影響範囲をある程度局所化するには、同一のコンポーネントであっても特定ベンダーの製品で統一することは避けるべきです。つまり、技術リスクの分散の観点からはマルチベンダー体制はメリットになります。また、複数ベンダーの製品を採用しても特定ベンダー製品の技術に依存せず、コモディティな技術を意識して採用することで様々なベンダー製品を選択できるようにもなりますし、設備調達において競争原理が働くため、結果的に調達コストの削減にも寄与します。コモディティな技術を採用することで、デリバリや保守管理といった運用面でも共通の管理ツールで統合管理できるなど、効率化が図れます。
技術リスクの分散化と合わせて、均一化に向けては異なるサービス基盤同士のベース機材の共通化を施策として推し進めています。これによって、部品を追加・変更するだけで異なるサービス基盤に流用しやすい状況を作っています。現在のサービス開発では、特殊な要件がない限りこの共通化の考え方がサービス基盤の物理設計に反映されています。共通化によって、各サービス基盤の余剰在庫も共通の在庫プールと見なすことができ、在庫リスクの低減にも貢献しています。また、採用するハードウェアについても、ここ数年海外のクラウドサービス事業者を中心に選択肢の増加がみられます。サーバ分野では、これまでの一般的なサーバベンダー製品を購入するほか、台湾を中心としたODM ベンダーに製造を依頼するケースや、「Open Compute Project(OCP)」から得られた知見を製品化したOCP認定サーバも市場に出荷され始めています。
IIJでは、自社で展開するクラウドサービス「IIJ GIO」のサービス基盤として用いるサーバは、一部のサービスを除きサーバベンダーが提供する汎用IAサーバを主に採用しています。もちろん、ODMベンダーのサーバ製品についても評価・検証を行っておりますが、サービス基盤としての要件と、調達規模から得られるコストメリットなどを総合的に比較した結果、現在の我々のクラウドサービスの基盤としてはサーバベンダー製品が適しているという判断に至っています。ただ、今後もこの判断が最適であるとは限りませんので、市場の変化に迅速に適応できるよう、我々は引き続き上記サーバベンダー製品、ODMベンダー製品、OCPサーバなどの動向を追っていきます。
ソフトウェアに対しては、我々はすべて自分たちで一から作ることは非効率で、ユーザメリットも少ないと考えています。商用製品・オープンソースソフトウェア(OSS)を問わず、お客様のニーズを踏まえながら市場に出ている良いプロダクトを採用し、サービスとして提供できることに価値があると考えています。ただ、クラウドサービス事業者が求める規模に対応していない場合は作り込みが必要になるなど、市場製品であるが故の苦労も多々あります。また、巷では2015年7月15日に延長サポートが終了するWindows Server 2003対応が話題になっていますが、商用製品はもちろん、OSSであってもサポート終了は常に付きまとう問題です。この問題について、IIJ GIOではサポート終了予定の製品を採用しているサービスの利用ユーザに対して、情報提供と注意喚起の取り組みを行っています。特に、エンタープライズ分野をターゲットとするプライベートクラウド系のIIJ GIOコンポーネントサービスでは、多数の商用製品を組み合わせたサービスを提供しており、ベンダーごとにサポートライフサイクルが定義されています。それらが常に動作保証されサポート可能な状態を保てるよう、「サービスライフサイクル」という形でサービスごとに各製品のサポートライフサイクルを一覧化し、定期的に最新情報に更新することで、ユーザが安心・安全にサービスを継続利用できるよう支援しています。ユーザのニーズはただ低コストでサービスを提供すれば満たされるというものでもなく、IIJはこのようなところにも注意を払っています。
継続的な技術開発の積み重ね
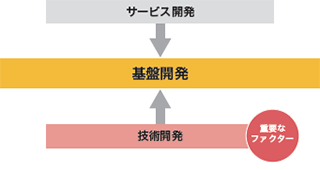
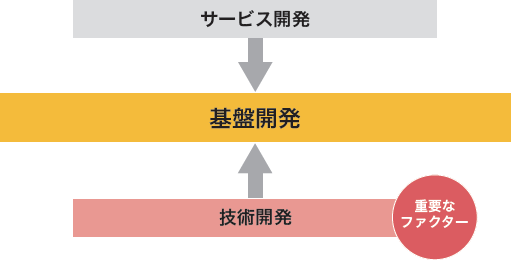
図-3 基盤開発のアプローチ
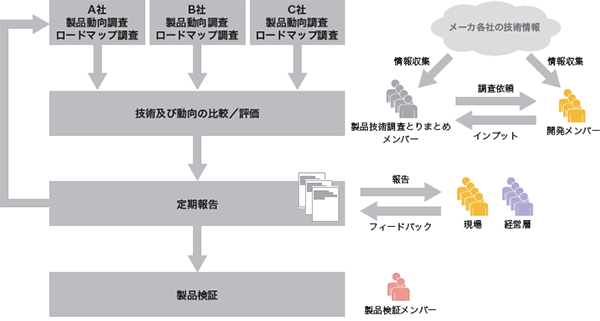
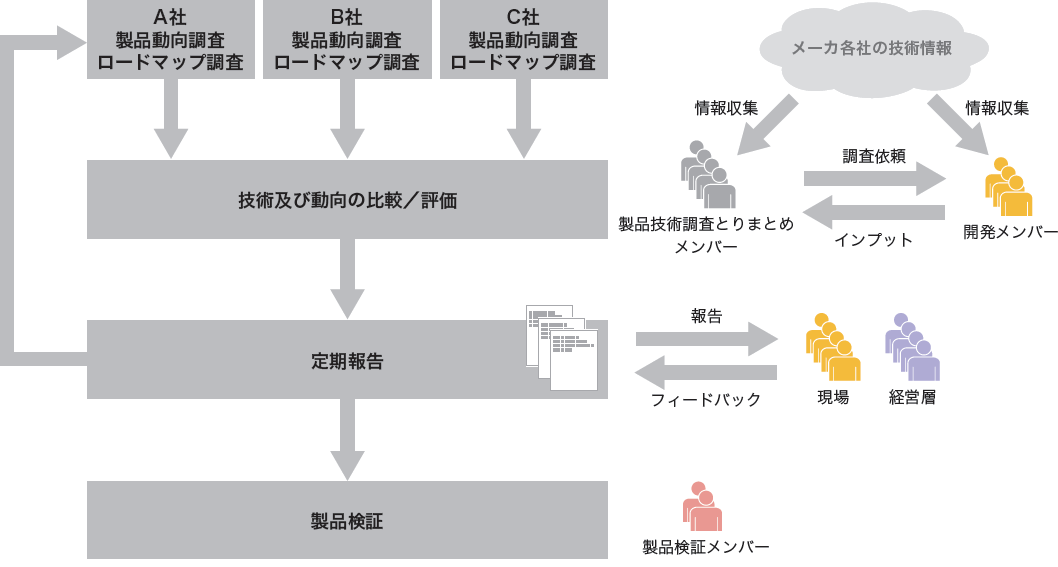
基盤開発とは、サービス開発におけるニーズと、蓄積された技術開発という2つの作用によって産まれます。特に、サービス開発のニーズを実現する最適な基盤を開発するためには、どれだけ日頃から様々な技術開発分野に知見と経験をもっているかにかかっています(図-3)。IIJでは、組織として「メーカ各社の製品動向やロードマップなどの情報収集」→「技術及び取り組み動向の比較/評価」→「定期報告」といった技術調査のサイクルを常に回しています。更に、報告に基いた開発現場や経営層からのフィードバックを参考にしながら、見込みのあるものについてはサービス運用に耐えられるかを見極めるため、社内での製品検証を行ったりもしています(図-4)。
{kind=link}
{kind=link}
図-4 技術動向調査プロセス
このように積み重ねた技術ナレッジと会社の事業戦略を踏まえて、サービス開発チームはサービスを企画・開発し、設計フェーズでは製品検証チームの検証結果を前提とした基盤設計をすることで、サービス品質の担保と設計期間の短縮の両立を図っています。調査対象は、サーバそのものはもちろんのこと、ストレージやネットワークなどのハードウェア系や、OS やハイパーバイザー、SDNなどのソフトウェア系、OpenStack、CloudStackなどの制御系など多岐にわたります。
継続的な取り組み事例としては、ハードウェアではサーバサイドフラッシュやIntelの次世代CPUへの追随が挙げられます。IIJでは新しい製品がリリースされる度にベンダーから評価機を入手し、世代ごとの性能特性の変化を把握するように努めています。同時に後継機種に変わることによるサービスへの影響や懸念点を洗い出し、サービス環境へのスムーズな導入に向けた指針を社内に展開しています。比較的新しい製品や製品サイクルの短い機種であっても、以上のように技術的な追随を継続することで、サービスニーズに応じ迅速に基盤に取り込んで提供することを可能にしています。ソフトウェアではマイクロソフトの早期導入プログラム(TAP)への参加が挙げられます。TAPに参加することで、Windows Serverオペレーティングシステム(OS)及びSystem Center管理製品の次期バージョンの設計目標、新機能、現行バージョンからの変更点、及び製品の導入やアップグレードについての理解を深めると共に、IIJがサービス開発要件として求める機能リクエストや仕様改善事項をフィードバックを行っています。以上の取り組みによって、発売後間もないタイミングで新バージョンのOSやハイパーバイザーを基盤インフラに取り込んで提供することができ、クラウドサービス事業者としての要望が取り入れられることで、バージョンが上がる度にサービスを意識したダウンタイムの少ない移行や運用も可能となります。
2.2.2 基盤運用
基盤開発、技術開発と並び重要なのが「基盤運用」です。ここでは基盤運用の主な内容である、「障害・不具合対応などの基盤維持活動」について紹介します。クラウドサービス事業者の設備においても、オンプレミスと同様にシステム障害は発生します。ただ、我々が遭遇するシステム障害は、リリースされて間もない新製品などを採用しているわけでもないのにマルチテナント環境として多数のユーザが様々な構成と使い方をするため、前例のない非常に稀な障害を引き当てることがあります。稀な障害であってもその場で済ますようなことはせず、その障害が基盤全体に影響を及ぼすものかどうか調査を行うと同時に、再発時に備えて一定期間の経過観察を実施します。障害原因を究明するのは時間とコストがかかりますが、初動対応時の見逃しが大規模障害に繋がるため、確実な対処法の確立を目指すのが我々の姿勢です。
障害・不具合対応などによる基盤維持活動
基盤維持活動とは、例えば「プロアクティブな保守対応」「根本原因への対策・対応」「リプレイス対応」などが挙げられます。
「プロアクティブな保守対応」では、サービスリリース後に発見された潜在的かつ致命的な不具合事象への予防保守対応のほか、ファームウェアやソフトウェアのサポートライフサイクルに追随するためのパッチ適用など、万が一の際に適切なベンダーサポートを受けるための保守対応の一環として実施しています。情報収集においては、一般的なセキュリティ情報は社内の情報共有サイトから日々発信されているほか、サービス基盤に採用している製品やテクノロジーに対しては、常に不具合・脆弱性情報をチェックする体制を敷いています。サポートライフサイクルについても同様です。ただ、我々はベンダー情報を鵜呑みにするわけではありません。本番サービス環境とほぼ同様の検証・ステージング環境を用いて、自社で作り込みした部分を含め既存環境への影響可否を慎重に検証した上で、サービス基盤の安定運用において重要と判断したものを選別して対応しています。なお、ベンダーが提供している仕組みやツールが大規模インフラへの展開を考慮していることは稀です。多くの場合、ファームウェアやパッチは1台1台手順に沿って適用することを前提に提供されているため、大量の設備に確実に展開するためには自動化などの工夫が求められます。こうしてみると、プロアクティブな保守対応は前項で紹介した技術開発のプロセスと非常によく似ていることが分かります。「根本原因対策対応」では、サービスリリース後に発生する基盤インフラ全体に影響を及ぼすような障害への対応です。先にも述べたとおり、我々は前例のない非常に稀なシステム障害に遭遇する場合があります。前例のない障害であっても、解決するには障害を再現させる必要があります。再現しないことにはベンダーサポートでは対策のとりようがありませんので、先に進みません。ただ、ベンダーサポートでは数台程度の検証機で再現試験をするため、我々が障害事象を伝えても再現しないケースがあります。障害の中には発生確率が非常に低く、再現させるために多くの試行回数を積み重ねる必要があるものも存在するからです。そこで、ときにはベンダーのサポートエンジニアに弊社に足を運んでもらい、実際に発生する様子を一緒に確認することで、粘り強く再現試験を継続するようお願いすることもあります。我々の環境で比較的再現しやすいのは、一般的に10台で100回試行しないと再現しないような障害であっても、我々は大量の設備を活かして様々なパターンを一度に実行できるところにあります。更に、これまでの運用経験の中で遭遇した大量の障害事象から、再現ノウハウを蓄積した弊社のエンジニアが再現試験に取り組むのです。我々は、その圧倒的な障害の再現性を基にベンダーサポートに働きかけ、いち早く改修してもらうことでより安定したサービス基盤となるよう、日々尽力しています。例えば、過去にサーバ設備を大量導入した際には、導入当初からNICの疎通障害が頻発したケースがありました。ベンダーサポートは「過去に事例がありません」の一点張りだったため、我々は障害事象を分析し、再現手順を確立して障害が発生する環境とその手順をベンダーサポートへ提示しました。すると、ベンダーサポートでも障害事象が確認でき、数ヵ月後には原因が判明しました。ベンダーサポートではBIOSやファームウェア、ドライバの更新、設定変更などでき得る限りの回避手段を提示してくれましたが、結局障害が収まることはありませんでした。最終的にベンダーが既存NICでの回避は困難と判断し、抜本的な対策として異なるメーカのNICへ交換されることになりました。
我々はこのように不具合の再現性を材料に、広範囲に及ぶ障害リスクを発見し、取り除くことを日々行っています。そして、以上のような基盤運用の苦い経験の積み重ねから、今日では技術リスクの分散はサービス基盤では必要不可欠な要件となっています。
「リプレイス対応」では、採用している機器のサポートライフサイクル切れに伴う、設備更改対応になります。企業のIT システムは、ハードウェアの保守やリースが切れる3 ~5年のサイクルでリプレースされることが一般的です。クラウドサービスを提供する我々サービス事業者であっても、(一部を除き)設備は一般的なITハードウェアベンダーから調達しており、設備の導入時期ごとに各ハードウェアベンダーの定める製品ライフサイクルに従い、(多少の延長などはあるものの)一定期間でリプレースを求められることに変わりはありません。例えば、Linuxベースの仮想サーバを提供するIIJ GIO ホスティングパッケージサービスの基盤では、拡張ディスクに使用するストレージ機器の保守サポート切れの問題に直面していました。現行のストレージ機器は、メーカーサポート終了とリースアップによる設備更改が必要だったためです。クラウドサービスの基盤に求められることは常に「ダウンタイムゼロの設備更改」ですが、今回のストレージ機器は「現行機種は異機種間のストレージ移行は未サポート、新機種ではそもそも移行機能が存在しない」という八方塞がりの状況でした。その問題の解決に向け我々が行ったのは、ハードウェアベンダーとの協業です。ベンダーとの数ヵ月に及ぶ協議を重ねることで、なんとか現行機種にて異機種間移行ができるよう機能追加の了承を得ました。更に一歩踏み込み、弊社個別に移行機能を提供してもらうのではなく、一般提供されているファームウェアを改修して機能追加してもらうことで、本移行機能の公式サポートを獲得することも実現しました。しかし、問題はこれで解決ではありませんでした。更なる課題として、移行作業をするのに1筐体あたり数百コマンドの実行が必要なことが判明しました。全台数では数万回に上ります。これを手作業で間違いなく実行することは到底不可能なため、新たに半自動化スクリプトを作成し、移行機能を確実に実行できる仕組みを準備しました。
以上のケースのように、ハードウェアベンダーと協業し利用者側のニーズを取り込むというのは経験・ノウハウが必要な領域です。また、作業の半自動化を含めこのような対応は利用者としては気づきにくいためあまり目立ちませんが、一顧客単独では得難いものです。このような点も、弊社のようなクラウドサービス事業者を利用する上での1つの利点ではないかと思います。
- 2.クラウドコンピューティングテクノロジー
ページの終わりです