ページの先頭です
- ページ内移動用のリンクです
- ホーム
- IIJの技術
- セキュリティ・技術レポート
- Internet Infrastructure Review(IIR)
- Vol.22
- 1.インフラストラクチャセキュリティ
Internet Infrastructure Review(IIR)Vol.22
2014年2月18日
- 目次
1.4 フォーカスリサーチ
インターネット上で発生するインシデントは、その種類や規模が時々刻々と変化しています。このため、IIJでは、流行したインシデントについて独自の調査や解析を続けることで対策につなげています。ここでは、これまでに実施した調査のうち、大容量メモリを搭載した端末のメモリフォレンジックにおける注意点、Forward Secrecy、WebクローラによるWebサイト改ざん調査の3つのテーマについて紹介します。
1.4.1 大容量メモリを搭載した端末のメモリフォレンジックにおける注意点
PCの高性能化が進むにつれて、ハードディスクやメモリの容量も増えてきています。デジタルフォレンジックにおいては、大容量化したメディアの解析をいかに効率よく行うかが1つの課題として知られていますが、大容量になることによって、揮発性のデータであるメモリのフォレンジック解析が不可能になる事象があることはあまり知られていません。本節ではその原因や、利用するメモリフォレンジックツールの注意点に関して述べたいと思います。なお、本稿で述べるメモリフォレンジックはWindows OSのみを対象にしています。
事象の原因
問題となる事象を説明する前に、メモリフォレンジック(※47)について簡単に説明します。メモリフォレンジックはディスクフォレンジックと同様に、最初にメモリ全体のバイナリデータを保存する「取得(もしくは保全)」と呼ばれる作業を行った後、取得したデータから情報を独自に抽出する「解析」の2つのフェーズから成り立っています。取得したメモリのバイナリデータはメモリイメージと呼ばれます。メモリイメージには、raw(メモリのデータをそのまま抽出したもの)、crashdump(メモリのデータからハードウェアに予約された領域を除去し、先頭にヘッダを付加したもの)、hibernation(休止状態からの復旧用で圧縮されたもの)の3種類の形式がありますが、現状、取得ツールは、rawもしくはcrashdump形式で保存するものしかありません。また、ほとんどの解析ツールはrawしか解析できず、crashdumpやhibernationを解析できるツールはごく僅かです。よって、端末のハードディスクに残っているhibernationを解析するようなケースを除いて、メモリフォレンジックとはraw(必要に応じてcrashdump)形式のメモリを取得・解析する技術であるといえます。
メモリフォレンジックの解析の過程でキーとなるデータはいくつかありますが、とりわけ以下の2つはどのような情報を抽出するにしても必要になります。
これらのデータを解析ツールが抽出するプロセスは、メモリイメージの形式によって異なります。rawの場合、それらを抽出するために各データのシグネチャを使ってメモリイメージ内を全検索します。一方、crashdumpは先頭のヘッダにそれらの情報を含んでいるため、データを検索する必要がありません。問題の事象は先に述べた2のデバッグ構造体を、raw形式のメモリの中から検索する際に起こります。x64アーキテクチャのWindowsがインストールされており、かつ大容量のメモリが搭載された端末(※50)において、そこから取得したメモリイメージ内にあるデバッグ構造体が、一定のアルゴリズムでエンコードされることがあります。その結果、解析ツールがデバッグ構造体を見つけられず、解析が異常終了します。
表-1 メモリイメージ取得ツールの検証結果
| FTK Imager |
Belkasoft Live RAM Capturer |
Windows Memory Reader |
winpmem | DumpIt | |
|---|---|---|---|---|---|
| raw | デコード しない |
デコード しない |
デコード しない |
デコード しない |
デコード しない |
| crashdump | - | - | デコード しない |
デコード しない |
デコード する |
取得ツールの検証
取得ツールの中には、取得時にエンコードされているデバッグ構造体をデコードするものが存在します。IIJではFTK Imager(※51)、Belkasoft Live RAM Capturer(※52)、Windows Memory Reader(※53)、winpmem(※54)、DumpIt(※55)の5つの取得ツールを検証し、デバッグ構造体をデコードするか否かの確認を行いました。その検証結果を表-1に示します。
結果から、DumpItが生成するcrashdump形式のみ、デコードされたデバッグ構造体のデータを含んでいることが分かりました(※56)。エンコードされたデバッグ構造体のデータとデコードされたそれを比較した図を図-12に示します。上がFTK Imagerで取得したエンコードされたデータで、下がDumpItで取得したデコードされたデータです。デコードされたデータの方では、デバッグ構造体のヘッダ(※57)にあるシグネチャとなる"KDBG"という文字列や、デバッグ構造体のサイズ情報を確認できます。

図-12 デバッグ構造体のデータ比較
使用する解析ツールがraw形式しか対応していない場合は、DumpItで取得したcrashdumpをrawに変換することで対応できます。ところで、Windows Memory Readerとwinpmemでは、crashdumpを生成することができます。crashdumpの場合、ファイルの先頭ヘッダに解析に必要な情報が入っていることは前述しました。ということは、crashdumpを変換せずに直接解析できるツールであれば、デバッグ構造体がエンコードされていても関係なく結果を返せるはずです。ところが、解析ツールによってはraw形式と同様に解析が異常終了してしまうものがあります。具体的には、Volatility Framework(※58)は、crashdumpの場合でもデバッグ構造体を検索してしまう実装のため、解析が失敗します(※59)。CrashDumpAnalyzer(※60)はcrashdumpのヘッダ情報のみを用いて解析を行うので、WindowsMemory Readerとwinpmemによって生成された(デバッグ構造体がエンコードされている)crashdumpも解析することができます。
まとめ
ここまで説明してきたように、メモリフォレンジックの取得・解析ツールは、一見同じ形式を取得・解析しているように見えて、その実装は大きく異なります。アナリストは、それらツールの特性を十分に理解した上で利用しないと、今回の事象のようにメモリフォレンジックから揮発性の情報を全く抽出できない状況に陥る可能性があります。日頃からツールを検証し、広く情報を収集し、問題が起きた場合にそれを見過ごすのではなく、真摯にその原因を追究していく姿勢が大切です。
1.4.2 Forward Secrecy
本稿ではNSAに関する一連の報道に伴い、注目されているForward Secrecyについて取り上げます。昨年末SNSなどの主要サイトにおいて、SSL/TLSサーバのForwardSecrecy対応が進められました。以下、Forward Secrecyが必要であると認識された背景、技術的解説、適用する際の注意点について紹介します。
Forward Secrecyが必要であると認識された背景
最近(Perfect)Forward Secrecy(※61)が注目を集めていますが、少なくともEUROCRYPT'89で発表された論文(※62)には登場していた概念です。暗号学的な定義はここでは解説しませんが、Diffie-Hellman(※63)などの鍵交換プロトコルを利用する手順において、そのセッションでしか利用しない一時的な鍵ペアを生成します。もし仮に、この一時的な公開鍵に対応する秘密鍵が漏えいしても、暗号通信が解読される範囲を一部に限定することができます。
一方で、毎回同じ公開鍵を用いて暗号化されているケースでは、一旦暗号化されたデータが広域ネットワークを通して伝播されている場合、暗号通信が何十年という単位で長期間に渡って記録され続けていて、将来のいつか秘密鍵が漏えいすることにより、過去に遡って復号できてしまいます。Forward Secrecyはこの問題を防ぐ技術として注目されています。
Forward Secrecyが注目されるきっかけとなったのは米国家安全保障局(NSA)による通信傍受に関する一連の報道です。昨年9月、米国国立標準技術研究所(NIST)が策定した暗号アルゴリズムの一部にNSAによるバックドアがあり、解読される可能性があるとの報道がなされました。NISTでは、意図的に脆弱な暗号を採用した可能性を否定する声明を発表し、擬似乱数生成アルゴリズムDual_EC_DRBGについて、利用しないことを推奨する勧告がなされています(※64)。また国内においても、CRYPTRECから本件が周知されました(※65)。これを受けて米EMC社は、デフォルトでDual_EC_DRBGが使用される設定になっていた暗号ライブラリRSA BSAFEの顧客に対して、本アルゴリズムを使用しないように伝えています(※66)。その後もEMC社とNSAに関する報道がなされました。Dual_EC_DRBGは、擬似乱数出力の32バイトを入手すれば、それ以後生成される乱数列を特定可能という脆弱性が2007年の時点で発表されていました(※67)。このような問題が発覚していたにも関わらず、暗号アルゴリズムの利用現場では使い続けられていたことになります。
攻撃者が擬似乱数生成モジュールを管理下に置くことで、通信時に用いられるあらゆる擬似乱数やそこから生成された暗号化用鍵に関する情報などを、リアルタイムに窃取する問題が考えられます。実際、擬似乱数生成モジュールのエントロピーが小さいことに起因する問題は、例えばDebianのOpenSSLにおける脆弱性などが知られています(※68)。この脆弱性は、Debianの特定バージョンにおけるOpenSSLを使って鍵生成を行った場合、極端に少ない鍵空間からしか秘密鍵を導出していないという問題です。この問題については2008年に指摘があったにも関わらず、現在でもその脆弱な鍵を利用しているサイトが存在しています。またAndroid上の一部のbitcoinアプリケーションにおいても、乱数生成時の問題が報告されています(※69)。bitcoinで用いられているECDSA署名では、署名演算を行うたびに、毎回ランダムな乱数パラメータを生成する必要があります。このとき異なる署名生成時に同じパラメータを使用した場合、秘密鍵が漏えいしてしまいます。これも擬似乱数のエントロピーの低さに起因する問題です。
暗号アルゴリズムにバックドアを仕掛ける方法以外にも、NSAによる通信傍受の仕組みが明らかになってきました。NSAが米Verizonに対し電話の通話記録の収集を求めていたこと、PRISMと呼ばれるインターネット上の動画・写真・電子メールなどのデータを監視するプログラムが、米国の主要なインターネット関連企業の協力のもと運用されていたことが昨年6月に報道されました。更に10月には、NSAによるリアルタイム通信傍受プロジェクトの存在が暴露され、Yahoo!とGoogleのデータセンター間の通信を盗聴していたことが公開されています。また、E-mailプロバイダであるLavabitは、FBIから秘密鍵供託を指示されたことから、利用者のプライバシーを保護することができなくなったと判断し、自らサービスを停止しました。このようにセキュアプロトコルを利用することで通信を暗号化していても、通信内容をNSAや他の組織に傍受されている可能性があることが、具体的な事例を通して認識されつつあります。昨年11月に開催されたIETF-88においても、Pervasive Surveillance(広域監視)がメイントピックとして取り上げられています(※70) (※71) (※72)。Forward Secrecyは、その対策方法の一つとして取り上げられるようになりました。
Forward Secrecyの概要
上述の問題は、ストレージの暗号化など、コンテンツセキュリティの分野においてはすでに認識されていました。一旦暗号化したデータがそのまま第三者に公開された時点で、ブルートフォース攻撃(総当たり攻撃)の対象となるためです。つまり、暗号化データの公開時点で対象データの解読を行うことが可能な状況下に置かれ、攻撃者はAESなどの共通鍵暗号方式においてすべての鍵で復号を試みることができます。一方で、署名については長期保存署名として規格化されており、タイムスタンプと併用してある時点の検証情報に更に署名していく形式により、長期間に渡り検証を可能にしています。しかし、データ暗号化については長期保存技術が確立していません。
一方でSSL/TLSなどのセキュア通信プロトコルにおいて、クライアントとサーバで確立したセキュアチャネルを流れるデータの完全性は、長期に渡って保証する必要がないため、長期署名の概念は必要ありません。しかし、機密性については上記に示したように、暗号通信が何十年という単位で長期間に渡って記録され続けることで破られる可能性があるため、それを保証する仕組みが必要になりました。セキュアデータストレージにおいては、遠い将来に復号するような状況が想定されるため、暗号化に用いた鍵を適切に管理する事が要求されています。一方で、セキュア通信プロトコルを用いて一時的に暗号化する場合には、暗号化に用いた鍵を保存しておく必要はありません。このように暗号鍵管理の観点においては大きく異なります。Forward Secrecyのアイデアは、この特徴の違いである「一時的に用いた鍵は捨ててもよい」ということを利用しています。
一般的なセキュア通信プロトコルやセキュアデータストレージでは、共通鍵暗号と公開鍵暗号の両方を用いるハイブリッド方式が使われています。実データの暗号化には共通鍵暗号が利用され、コンテンツ鍵(データ暗号化に用いられる鍵)は公開鍵暗号で暗号化されています。例えば、AES暗号で用いたコンテンツ鍵を、RSA公開鍵で暗号化を行うという手順がその一例です。
SSL/TLSでは、鍵交換アルゴリズムとしてRSA、DH_RSA、DHE_RSAなどが定められています。鍵交換アルゴリズムは、コンテンツ鍵やMAC用鍵を導出するための元データを安全に共有するために用いられます。例えば、鍵交換アルゴリズムとしてRSAを選択した場合には、PreMasterSecretを安全に共有します。PreMasterSecretはクライアントが作成するランダムデータで、サーバ証明書に格納されている公開鍵を用いて暗号化することで、安全にサーバと共有することができます。つまりRSA暗号をサーバ認証と鍵交換の両方に利用しています。またDH_RSAでは、証明書に含まれているDH公開鍵を用いてDH鍵交換アルゴリズムにより安全なデータ共有を行います。一方でDHE_RSAでは、その都度異なる一時的なDH公開鍵・秘密鍵を生成します(※73)。
ここで、サーバ証明書に記載の公開鍵に対応する秘密鍵が後日漏えいしたケースを考えます。鍵交換アルゴリズムがRSAまたはDH_RSAの場合、固定された公開鍵を用いて鍵交換を行っていたため、暗号化された通信内容を長期的に盗聴されていた場合、その記録からコンテンツ鍵を導出できます。そのため暗号通信データから当時の通信内容が暴露してしまいます。

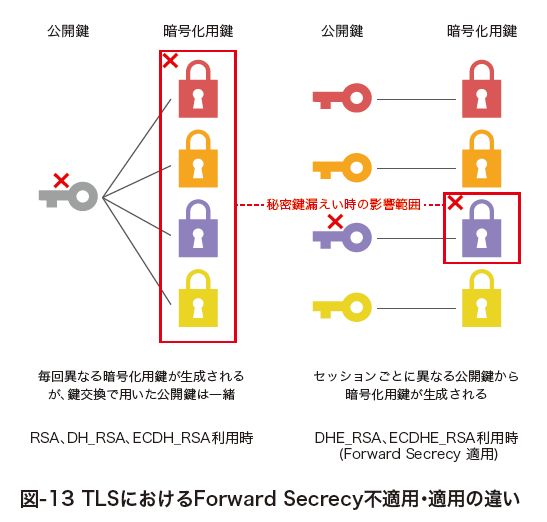
一方でDHE_RSAでは、セッションごとにDH公開鍵・秘密鍵を生成しその都度捨ててしまうため、暗号通信データを復号するにはその通信に利用されていたDH秘密鍵の解読が必要となります。もし仮にDH秘密鍵の解読がされたとしても、対応するDH公開鍵を用いて安全に導出したコンテンツ鍵で暗号化された通信のみが暴露され、被害を限定的にすることができます。図-13は暗号化用鍵を導出するために利用された公開鍵の対応付けを表現しています。これは公開鍵に対応する秘密鍵が解読された際に暴露される暗号化用鍵の対応付けについて表現しているとも言えます。DHE_RSAの利用は、使い捨ての公開鍵をその都度作成して暗号通信を行っていることを意味します。このとき、一時的に生成されたDH公開鍵はサーバによるRSA署名により保証されており、DH鍵交換アルゴリズムが潜在的に持つ中間者攻撃への弱さを防いでいます。
TLSにおいては、1999年に策定されたRFC2246(TLS1.0)から、Forward Secrecyが適用可能なCipherSuiteが定められています(※74)。最近では、DHの楕円曲線版であるECDHも利用されています(※75)。ECDHは2006年に策定されたRFC4492より利用可能となっており、Forward Secrecy対応の鍵交換アルゴリズムとしてはECDHE_*として記述されています(※76)。一般的にはDHよりもECDHが高速処理できるため、様々なクライアントやサーバにおいてECDHの利用が広がっています。
Forward Secrecyの適用事例と注意点
2011年から対応しているGoogle(※77)をはじめとして、2013年にはFacebook(※78)、Twitter(※79)、GitHub(※80)などがForward Secrecy対応または対応中であることを表明しています。またEFF(Electronic Frontier Foundation)により主要サイトの対応状況が随時更新されています(※81)。これらの対応に呼応する形で、技術者向けにApache+SSLなどでの具体的な設定方法例も紹介されています(※82)。しかし、Forward Secrecyを適用しても完全にPervasive Surveillanceを防ぐことはできません。以下Forward Secrecyを適用したとしても、防ぎきれない問題点について触れます。
まず、(EC)DH鍵交換アルゴリズムについての潜在的問題について説明します。サーバへの侵入などを通してRSA秘密鍵が漏えいした、またはRSAアルゴリズムが危殆化した時点で、Forward Secrecyに対応し使い捨て公開鍵を利用していたとしても、それ以降の暗号通信が漏えいする場合があります。例えばTLSにおける鍵交換アルゴリズムとしてDHE_RSAを利用する場合を考えます。クライアントはサーバから送られてきた一時的なDH公開鍵の正当性を確認しますが、クライアントとサーバに割り込んだ攻撃者はRSA秘密鍵を入手しているため、サーバから送信するDH公開鍵を書き換えることができ、中間者攻撃が可能となります。そのためRSA鍵が危殆化した場合、それ以降の暗号通信は解読可能となります。この場合、RSA鍵ペアとサーバ証明書の更新により対策することができます。
次に擬似乱数生成モジュールの問題について触れます。2013年に改訂された新しい電子政府推奨暗号リストでは、擬似乱数生成アルゴリズムのカテゴリ自体削除されており、電子政府システムや民間の情報システムにおいて、どのような擬似乱数を利用すべきかについては再考する必要があります。疑似乱数生成アルゴリズムの利用については、旧版のリストに対応したガイドラインに記載がありましたが、その後更新されておらず現在有効とはいえません(※83)。擬似乱数生成アルゴリズムには、互換性の確保が必要ではないという理由により、リストからカテゴリが削除されていると考えられますが、リストから削除されていても、どのような点に注意して利用・実装を行うべきかについての指針が望まれています。
乱数生成モジュールは、多くの場合、暗号ライブラリを通して利用されます。その暗号ライブラリの認定制度としては、CMVP(※84)、JCMVP(※85)があり、これらを活用することで安全に利用できると考えられます。しかし、前述したRSA BSAFEは政府機関のお墨付きを得ている暗号ライブラリだったにも関わらず、問題があったことが露呈しています。暗号ライブラリとして安全が確認されていても、擬似乱数生成モジュールに入力するSeedやNonceが短いなど、利用上の問題が発生していないかについて気を付ける必要があるでしょう。

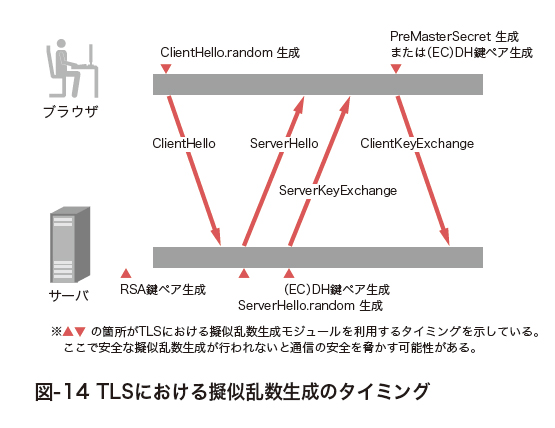
図-14はTLSプロトコルにおいて擬似乱数モジュールを使うフェーズについてまとめたものです。TLSを利用する前にサーバはRSA鍵ペアを生成しサーバ証明書を作成します。その際にはサーバが擬似乱数生成モジュールを用いて素数を生成しますが、前述したDebian OpenSSL問題のように十分なエントロピーを確保する必要があります。TLSプロトコルはクライアントとサーバそれぞれでHelloを送信することから始まります。ClientHelloおよびServerHelloのメッセージ送信においてそれぞれ28バイトのランダムデータを含むrandomを生成します。さらに鍵交換アルゴリズムとしてRSAを選択した場合には、46バイトのランダムデータを含むPreMasterSecretをClientKeyExchangeメッセージを通して安全に共有します。またDHEやECDHEを利用する場合には一時的なDH鍵またはECDH鍵を生成して鍵交換アルゴリズムを実行しPreMasterSecretを共有します。このとき一時的な(EC)DH秘密鍵の選択範囲が少ないと、解読される危険性が増します。最後にClientHello.random、ServerHello.random、PreMasterSecretの3つのランダムデータからMasterSecretを算出します。このMasterSecretから、クライアントとサーバそれぞれのMAC鍵、コンテンツ鍵、(CBC暗号モード利用時の)初期ベクトル(IV)を導出することで安全な通信を行うことができます。TLSでは複数のランダムデータを利用して暗号化用鍵を導出する構造を持つ設計がなされていますが、安全に擬似乱数生成ができない、つまり生成される値に偏りがあるケースにおいてはTLSが安全に利用できなくなる可能性があります。
1.4.3 WebクローラによるWebサイト改ざん調査
IIJでは、マルウェア対策活動MITF(Malware Investigation Task Force)の一環として、Webサイト改ざん状況の調査及びドライブバイダウンロード型マルウェアの収集を目的とするWebクローラを2008年から運用しています。本稿では、現在のWebクローラ環境の概要と、最近の観測傾向を紹介します。
Web改ざん事案の増加とWebクローラ
2013年6月、IPAや警察庁が相次いでWebサイト改ざんに関する注意喚起を公開しました(※86)。また、JPCERT/CCのレポートによれば2013年10月から12月の期間には、2,774件のWeb改ざん事案が報告されました(※87)。
近年のWebサイト改ざん事案は、コンテンツの書き換えそのものを目的とする愉快犯や政治犯ではなく、iframeタグなどをコンテンツに挿入して、閲覧者をマルウェア配布サイトに誘導することを目的とするものが多数を占めています。この種のWeb改ざん事案は、2008年のGumblar事件(※88)以降、国内外で広く発生するようになり、その後も継続していましたが、2013年は特に国内の事案が増加しています(※89)。一般に安全と考えられがちな著名サイトや人気サイトが改ざんされ、多くの閲覧者を危険な状態にしてしまった事例も複数発生しています。MITFではこのような状況において、有効な対策を実施するために、Web改ざんの動向を把握するための調査を行っています。
あるWebサイトが、閲覧者にマルウェアを感染させるような改ざん被害を受けているかどうかを調査するためには、通信のキャプチャや、アクセス先の一覧及びコンテンツの収集が可能で、確認が終わったら簡単に元の状態に戻すことができる環境を構築した上で、実際にWebブラウザを起動して手動で閲覧し、マルウェアに感染するか試してみるのが一番です。しかし、毎日多数のWebサイトを手動で閲覧し、マルウェア感染の有無を確認しようとすると膨大な手作業が必要となるため現実的ではありません。MITFのWebクローラは、このような作業を自動化する仕組みです。
クライアントハニーポットとその種類
MITFのWebクローラは、ドライブバイダウンロード(※90)によってマルウェアに感染する脆弱なクライアント、もしくは脆弱性を模擬する環境を用いて、調査対象のWebサイトを巡回する仕組みです。これは、クライアントハニーポットと呼ばれるシステムで、この環境からマルウェア感染が行われるように改ざんされたWebサイトを閲覧した場合には、改ざんされたコンテンツや、攻撃に用いられるファイル、攻撃者が感染を意図したマルウェアなどを収集することができます。
一般に、クライアントハニーポットは、実環境を模倣する方法によって大きく2種類に分類されます。
- 1)高インタラクション型クライアントハニーポット
- Windows環境など、通常利用されるクライアントと同等のシステムを用意して対象Webサイトを閲覧し、ダウンロードされるコンテンツを収集します。一般のクライアント環境で閲覧した場合とほぼ同一の正確な情報が得られる反面、低インタラクション型に比べて個々のサイトの巡回に要する時間が長いことや、実際にマルウェアに感染してしまうため、毎回元の状態に戻す手間がかかること、システムの構築、運用に手間がかかる(特に複数バージョンのクライアント環境を用意する場合などは更に多くの手間がかかる)などのデメリットがあります。
- 2)低インタラクション型クライアントハニーポット
- Webブラウザなどのクライアントアプリケーションをエミュレーションするツールを利用して、対象Webサイトのコンテンツを収集します。システムの構築、運用が容易で、巡回が高速なことに加え、あくまで脆弱性を模倣して攻撃コンテンツを収集するため、実際にマルウェアに感染することはないというアドバンテージがありますが、JavaScriptエンジンの実装の問題などにより、実環境の動作を再現できない場合があることや、ドライブバイダウンロードによって攻撃されるすべての機能(脆弱性)をエミュレーションするものではないため、攻撃の結果としてダウンロードされるペイロードを収集することが難しいなどのデメリットがあります。
IIJではこれら2種類のクライアントハニーポットについて多くの実装を検証してきましたが、低インタラクション型クライアントハニーポットでは、主に再現性の面で十分な機能を備えた実装が存在しなかったため、現在は独自の高インタラクション型クライアントハニーポットを構築、運用しています。
リダイレクションの識別によるドライブバイダウンロード検出
クライアントハニーポットによる巡回後、個々のサイト閲覧時にドライブバイダウンロードが発生したか否かを判別する必要があります。しかし、Webコンテンツ改ざん時に挿入されるコードや攻撃成功時にダウンロードされるペイロードは頻繁に変更される場合が多いため、シグネチャペースの仕組みで最新の攻撃を検出することは困難です。そこで、MITFのWebクローラは、閲覧時に発生する通信の表層的な特徴を抽出することでドライブバイダウンロードの有無を分析し、攻撃が行われたと判定された場合には、サンドボックスで更に詳細な解析を行う仕組みになっています。

図-15 改ざんWebサイト閲覧時の通信先フローの例
例えば、図-15は改ざんされたWebサイトを閲覧してドライブバイダウンロードが発生した際の典型的な接続先遷移を示したものですが、クライアントは、当初閲覧を意図したwww.example.jpとは異なるドメインの、3つのサーバに接続しています。また、それらの外部ドメインのサーバからPDFやJava(JAR)、Windows実行形式(EXE)など、通常のWeb閲覧では自動的にロードされることが稀な種類のコンテンツを取得しています。このため、ドメイン外へのリダイレクションを識別し、リダイレクション先との通信時のHTTPヘッダ情報(コンテンツタイプやファイルサイズ、User-Agentなど)を、あらかじめ設定したドライブバイダウンロードの特徴情報に基づいて評価することで、攻撃の有無を比較的高速に判別することが可能です(※91)。そして、当該Webサイトが改ざんされている可能性があると判定した場合は、更にマルウェアの動的解析環境で閲覧時のシステムの挙動(利用するAPIや、ファイル、レジストリの書き込み内容など)を自動分析し、攻撃の有無及び内容について精度の高い情報を記録しています。
巡回対象と最近の観測傾向
現在、MITFのWebクローラは国内の著名サイトや人気サイトなどを中心とした数万のWebサイトを日次で巡回しています。さらに、クローラの処理能力を調整しながら、巡回対象を順次追加しています。また、一時的にアクセス数が増加したWebサイトなどを対象に、一時的な観測も行っています。

{kind=link}
{kind=link}
{kind=link}
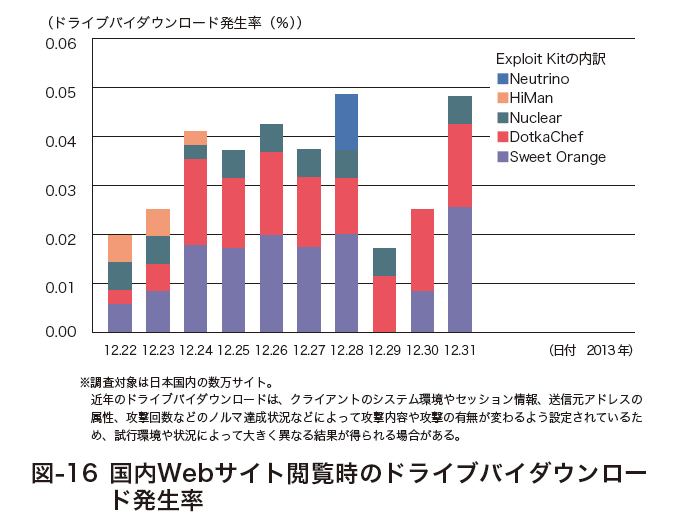
図-16 国内Webサイト閲覧時のドライブバイダウンロード発生率
※調査対象は日本国内の数万サイト。
近年のドライブバイダウンロードは、クライアントのシステム
環境やセッション情報、送信元アドレスの属性、攻撃回数などの
ノルマ達成状況などによって攻撃内容や攻撃の有無が変わるよう
設定されているため、試行環境や状況によって大きく異なる結果
が得られる場合がある。
2013年12月22日から31日の観測結果をまとめたものが図-16です。縦軸がWebサイト閲覧時のドライブバイダウンロード発生率を百分率で示し、更に、その内訳をExploit Kitの種類ごとに色分けしています。
この期間中に観測された攻撃の多くはSweet OrangeまたはDotkaChefが利用されています。WebクローラがダウンロードしたExploit及び、これらのExploit Kitの特徴(※92)から、日本国内のクライアントに対しては、主としてJREやIEの脆弱性を狙われているものと推測されます。また、この時期に観測した改ざんWebサイトには、改ざんされたコンテンツのURLや、改ざん内容などの特徴から、FTPなど正規のサーバ接続権限を奪われた上でコンテンツファイルまたはサーバ実行ファイルを改ざんされたと推測されるものや、2013年12月18日に公開されたOpenXの脆弱性(※93)を悪用して改ざんされたと推測されるものなどがありました。
このように、多数のWebサイトを巡回してドライブバイダウンロードを集計することで、改ざんサイトの増減や悪用される脆弱性の傾向などを把握できるようになり、予防策の優先順位が検討しやすくなりました。今後、このような観測傾向をIIRで定期的に公開するために、更にシステムの調整を進めています。また、改ざんを識別した個別事案に関しては、主にお客様やその関係者、場合によっては一般のインターネット利用者に対して迅速かつ効果的に報告や対応支援などを実施できるよう、運用体制の検討を進めています。IIJでは、今後もマルウェア対策を推進するため、状況の変化に応じてシステムを更新し、適切に対応していきます。
- (※47)IIJ-SECT Security Diaryでは、SpyEyeを例としてマルウェアに感染した端末のメモリを調査する手法を解説している。「メモリフォレンジックによるマルウェア感染痕跡の調査」(https://sect.iij.ad.jp/d/2011/12/194028.html
 )。
)。 - (※48)DirectoryTableBaseとして定義されている。
- (※49)_KDDEBUGGER_DATA64として定義されている。
- (※50)IIJでは16GBのメモリを搭載したx64アーキテクチャのWindows7端末で事象を確認している。後で述べる、デバッグ構造体をデコードする独自のロジックを組み込んだ取得ツール(DumpIt)の作者であるMatthieu Suicheによると、OSはVista以降であれば起こりうる事象であるとのこと。
- (※51)バージョン3.1.4.6を利用(http://www.accessdata.com/support/product-downloads)。
- (※52)(http://forensic.belkasoft.com/en/ram-capturer)。
- (※53)バージョン1.0を利用(http://cybermarshal.com/index.php/cyber-marshal-utilities/windows-memory-reader)。
- (※54)バージョン1.4.1を利用(http://sourceforge.net/projects/volatility.mirror/files/?source=navbar)。
- (※55)バージョン2.0を利用(http://www.moonsols.com/windows-memory-toolkit/)。
- (※56)IIJによる検証では、列挙したツールの中でDumpItのcrashdump形式のみが、デコードされたデバッグ構造体を含んでいたが、同じOS環境・ツールで取得した場合でも異なる結果になる可能性がある。例えば以下の記事では、FTK ImagerやBelkasoft RAMCaptureによって取得されたメモリイメージを解析できたことが報告されている(ただし、作者は明示的にデバッグ構造体がエンコードされていることを確認しているわけではないようなので、これらのツールが明示的にデコードしたのではなく、この端末ではそもそもエンコードされていなかった可能性も考えられる)。このように、デバッグ構造体がエンコードされる条件は、Windows7以前のOSでは明確になっていない。BriMor Labs、"All memory dumping tools are not the same("(http://brimorlabs.blogspot.jp/2014/01/all-memory-dumping-tools-are-not-same.html)。
- (※57)_DBGKD_DEBUG_DATA_HEADER64として定義されている、_KDDEBUGGER_DATA64の先頭にあるヘッダ。
- (※58)オープンソースのPythonで書かれたメモリ解析ツール。raw/crashdump/hibernation全てに対応している。Volatilityはプロセス構造体をリストする際、どの形式でも必ずデバッグ構造体を検索するジェネレータを使う仕様になっているため、それがエンコードされていると解析が失敗する。(https://code.google.com/p/volatility/)。
- (※59)以下の記事によると、Volatility Frameworkでは、解析中にデバッグ構造体をデコードするコードを試験的に実装しており、トレーニング参加者には配布される予定との
こと。デバッグ構造体がエンコードされてしまう事象は、Windows8やServer 2012などの新しいOSにおいては、メモリのサイズにかかわらず起こりうると述べている。
Volatility Labs、"The Secret to 64-bit Windows 8 and 2012 Raw Memory Dump Forensics"(http://volatility-labs.blogspot.jp/2014/01/the-secret-to-64-bit-windows-8-and-2012.html)。
- (※60)EnCaseの拡張スクリプト言語であるEnScriptで書かれたcrashdump解析ツール。Volatilityに比べると抽出できる情報は限定的。(http://takahiroharuyama.github.io/blog/2014/01/05/some-old-stuffs/)。
- (※61)Perfect Forward SecrecyとForward Secrecyの二つの言い方が存在しているが、両者とも同じ意味・文脈で利用されているため、本稿ではForward Secrecyに統一している。
- (※62)Christoph G. Günther, "An Identity-Based Key-Exchange Protocol", EUROCRYPT1989, LNCS vol.434, pp.29-37, 1989.
- (※63)一般的なDiffie-Hellman鍵共有方式は以下のとおりである。十分大きな素数pに対して有限体GF(p)の生成元gを定め、p及びgを公開パラメータとする(秘密にしておく必要はない)。ユーザAとユーザBはそれぞれ秘密鍵x,yを1からp-1の整数からランダムに選択し、X=gx mod pとY=gy mod pをユーザA及びBの公開鍵としてお互いに開示する。ユーザAはユーザBの公開鍵Yを用いてYx = (gy)x mod pを計算できる。一方でユーザBはユーザAの公開鍵Xを用いてXy = (gx)y mod pを計算できることからgxy mod pをユーザAとBだけで秘密裏に共有することができる。g, gx,pからxを求める離散対数問題は十分大きな素数pにおいて困難とされている。
- (※64)NIST、"SUPPLEMENTAL ITL BULLETIN FOR SEPTEMBER 2013"(http://csrc.nist.gov/publications/nistbul/itlbul2013_09_supplemental.pdf
 )。
)。 - (※65)CRYPTREC、擬似乱数生成アルゴリズムDual_EC_DRBGについて(http://www.cryptrec.go.jp/topics/cryptrec_20131106_dual_ec_drbg.html)。
- (※66)ArsTechica、"Stop using NSA-influenced code in our products, RSA tells customers"(http://arstechnica.com/security/2013/09/stop-using-nsa-influencecode-in-our-product-rsa-tells-customers/?comments=1&post=25330407#comment-25330407)。
- (※67)Dan Shumow、Niels Ferguson、"On the Possibility of a Back Door in the NIST SP800-90 Dual Ec Prng"、Rump session in CRYPTO2007(http://rump2007.cr.yp.to/15-shumow.pdf)。
- (※68)Debian Security Advisory、"DSA-1571-1 openssl -- predictable random number generator"(http://www.debian.org/security/2008/dsa-1571)。同様の事例はIIR Vol.17(http://www.iij.ad.jp/dev/report/iir/pdf/iir_vol17.pdf)の「1.4.1 SSL/TLS、SSHで利用されている公開鍵の多くが他のサイトと秘密鍵を共有している問題」にて紹介している。
- (※69)bitcoin.org、"Android Security Vulnerability"(http://bitcoin.org/en/alert/2013-08-11-android)。また本件に関して以下の論文で実被害が観測されている。Joppe W. Bos、J. Alex Halderman、Nadia Heninger、Jonathan Moore、Michael Naehrig、Eric Wustrow、"Elliptic Curve Cryptography in Practice"(https://eprint.iacr.org/2013/734)。
- (※70)IETF Blog、"We Will Strengthen the Internet"(http://www.ietf.org/blog/2013/11/we-will-strengthen-the-internet/)。
- (※71)CA Security COUNCIL Blog、"IETF 88 - Pervasive Surveillance(https://casecurity.org/2013/11/26/ietf-88-pervasive-surveillance/)。
- (※72)"IETF 88 Technical Plenary: Hardening The Internet"(https://www.youtube.com/watch?v=oV71hhEpQ20)。
- (※73)DHE_*のEはEphemeralに由来する。RFCで定められているServerDHParamsの構造は最大216ビット長の素数p、生成元g、公開鍵Y=gy(yは秘密鍵)の3つを格納し送付できるように設計されている。
- (※74)The TLS Protocol Version 1.0(http://www.ietf.org/rfc/rfc2246.txt)。
- (※75)具体的なアルゴリズムは"Special Publication 800-56A, Recommendation for Pair-Wise Key Establishment Schemes Using Discrete Logarithm Cryptography"(http://csrc.nist.gov/publications/nistpubs/800-56A/SP800-56A_Revision1_Mar08-2007.pdf)の5.7.1節に記載されている。DHと同じく楕円曲線上の離散対数問題を安全性の根拠に置いている。
- (※76)Elliptic Curve Cryptography (ECC) Cipher Suites for Transport Layer Security (TLS)(http://www.ietf.org/rfc/rfc4492.txt)。
- (※77)Google Online Security Blog、"Protecting data for the long term with forward secrecy"
(http://googleonlinesecurity.blogspot.jp/2011/11/protecting-data-for-long-term-with.html)。 - (※78)Facebook Engineering、"Secure browsing by default"(https://www.facebook.com/notes/facebook-engineering/secure-browsing-by-default/10151590414803920)。
- (※79)The Twitter Engineering Blog、"Forward Secrecy at Twitter"(https://blog.twitter.com/2013/forward-secrecy-at-twitter-0)。
- (※80)The GitHub Blog、"Introducing Forward Secrecy and Authenticated Encryption Ciphers"(https://github.com/blog/1727-introducing-forward-secrecy-andauthenticated-encryption-ciphers)。
- (※81)Electronic Frontier Foundation、"UPDATE: Encrypt the Web Report: Who's Doing What"(https://www.eff.org/deeplinks/2013/11/encrypt-web-reportwhos-doing-what#crypto-chart)。
- (※82)Qualys Community、"Configuring Apache, Nginx, and OpenSSL for Forward Secrecy"(https://community.qualys.com/blogs/securitylabs/2013/08/05/configuringapache-nginx-and-openssl-for-forward-secrecy)。一部のCipherSuiteはTLS1.1やTLS1.2でしか使えないものもあるためOpenSSLなど暗号アルゴリズムの対応状況に依存する。例えばOpenSSLではバージョンが1.0.0h以降のライブラリでTLS1.2対応である。またOpenSSLではRFCで記載されているCipherSuiteと異なる記載方法が採用されている点にも注意(http://www.openssl.org/docs/apps/ciphers.html#CIPHER_SUITE_NAMES)。
- (※83)電子政府推奨暗号の利用方法に関するガイドブック(http://www.cryptrec.go.jp/report/c07_guide_final_v3.pdf)にはいくつかのセキュアプロトコルでの利用に際して、同一の値が生成されないよう生成される値に十分な長さがあること、生成される値に偏りがないこと、生成される値が予測できないこと、という要件に関する記載がある。また2009年度版リストガイド(http://www.cryptrec.go.jp/report/c09_guide_final.pdf)第6章に擬似乱数生成器の章が設けられている。
- (※84)Cryptographic Module Validation Program(CMVP)(http://csrc.nist.gov/groups/STM/cmvp/)はNISTが設立した暗号モジュールの試験制度である。
- (※85)暗号モジュール試験及び認証制度(Japan Cryptographic Module Validation Program(http://www.ipa.go.jp/security/jcmvp/)はCMVPの日本版であり、情報処理推進機構で運用されている。また、JCMVPとCMVPは相互に認証された製品を認める共同認証が適用されている(http://www.ipa.go.jp/about/press/20120227.html)。
- (※86)IPA、_「ウェブサイト改ざんの増加に関する一般利用者(ウェブ閲覧者)向け注意喚起」(http://www.ipa.go.jp/security/topics/alert20130626.html)及び「ウェブサイト改ざん等のインシデントに対する注意喚起~ウェブサイト改ざんが急激に増えています~」(http://www.ipa.go.jp/security/topics/alert20130906.html)、警察庁、「改ざんウェブサイト閲覧によるマルウェア感染に関する注意喚起について」(http://www.npa.go.jp/cyberpolice/detect/pdf/20130626.pdf)。
- (※87)JPCERT/CC、「JPCERT/CCインシデント報告対応レポート[2013年10月1日~ 2013年12月31日]」(http://www.jpcert.or.jp/pr/2014/IR_Report20140116.pdf)。
- (※88)Gumblarについては、本レポートのVol.4(http://www.iij.ad.jp/dev/report/iir/pdf/iir_vol04.pdf)の「1.4.2 ID・パスワード等を盗むマルウェアGumblar」及びVol.6(http://www.iij.ad.jp/dev/report/iir/pdf/iir_vol06.pdf)の「1.4.1 Gumblarの再流行」で詳しく解説をしている。
- (※89)2013年3月の国内Webサイト改ざん事案については、本レポートのVol.19(http://www.iij.ad.jp/dev/report/iir/pdf/iir_vol19.pdf)の「1.4.2 日本国内のWebサイト改ざんとドライブバイダウンロード」で詳しく解説している。
- (※90)ドライブバイダウンロードとは、Webコンテンツを閲覧した際に、ユーザに無許可でソフトウェア(主にマルウェア)をインストールする行為。Webブラウザやプラグインなどの脆弱性を悪用して行われることが多い。
- (※91)多くのWebサイトでは、外部ツールや広告などのマッシュアップコンテンツなど、運営者が意図して配置したドメイン外コンテンツが利用されているため、これらのホワイトリストなども設定する必要がある。
- (※92)最近活発なExploit Kitの概要は「An Overview of Exploit Packs (Update 20) Jan 2014」(http://contagiodump.blogspot.jp/2010/06/overview-of-exploit-packs-update.html)などに詳しくまとめられている。
- (※93)「Zero Day Vulnerability in OpenX Source 2.8.11 and Revive Adserver 3.0.1」(http://www.kreativrauschen.com/blog/2013/12/18/zero-day-vulnerability-in-openx-source-2-8-11-and-revive-adserver-3-0-1/)。
- 1.インフラストラクチャセキュリティ
ページの終わりです