ページの先頭です
- ページ内移動用のリンクです
- ホーム
- IIJの技術
- セキュリティ・技術レポート
- Internet Infrastructure Review(IIR)
- Vol.60
- 2. フォーカス・リサーチ(1)システムソフトウェアの通信分野における2010年頃からの研究まとめ
Internet Infrastructure Review(IIR)Vol.60
2023年9月26日発行
- 目次
2. フォーカス・リサーチ(1)
システムソフトウェアの通信分野における2010年頃からの研究まとめ
2.1 概要
2010年代初頭より10Gbpsを超えるような速度のネットワークインタフェースカード(NIC)が一般化し、データセンターなどで広く利用されるようになりました。NICの性能向上により、それらハードウェアを制御するシステムソフトウェアと呼ばれるようなソフトウェアの、特に通信に関する処理の効率の重要性が高まり、研究コミュニティにおいては性能の改善を目指した取り組みが数多く行われてきました。
本稿では、まず2.2でシステムソフウェアにおける通信処理の挙動について触れ、次に2.3では過去の研究がそれらをどのように高速化しようと取り組んできたかについてまとめます。それらをふまえて、2.4で、IIJ技術研究所が近年行っている取り組みについて紹介します。
注意として、2.4で述べている取り組みは研究段階のものであり、IIJサービス・インフラに組み込まれているものではないことを、最初に申し上げておきます。
2.2 通信に関連したプログラムの主な挙動
まず、2.2.1で汎用OS内での通信の関わりについて、次に2.2.2で、データセンターで一般的に利用される仮想マシンが通信を行う場合の処理について述べます。
2.2.1 汎用OS内での通信関連の処理
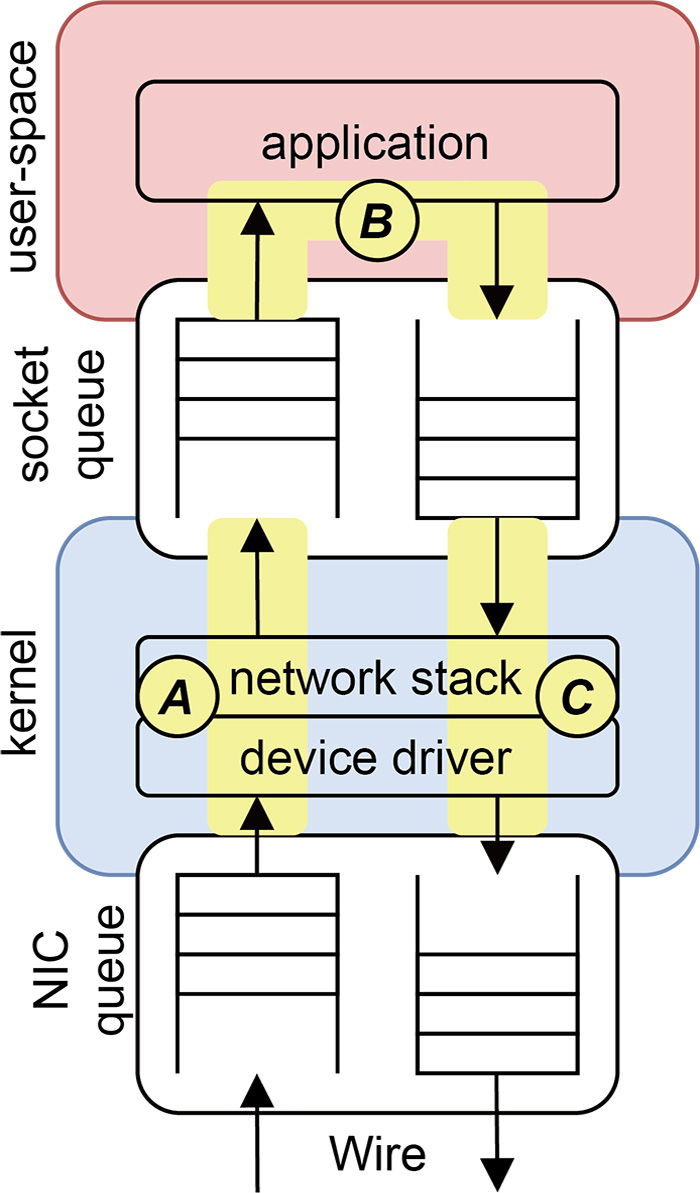
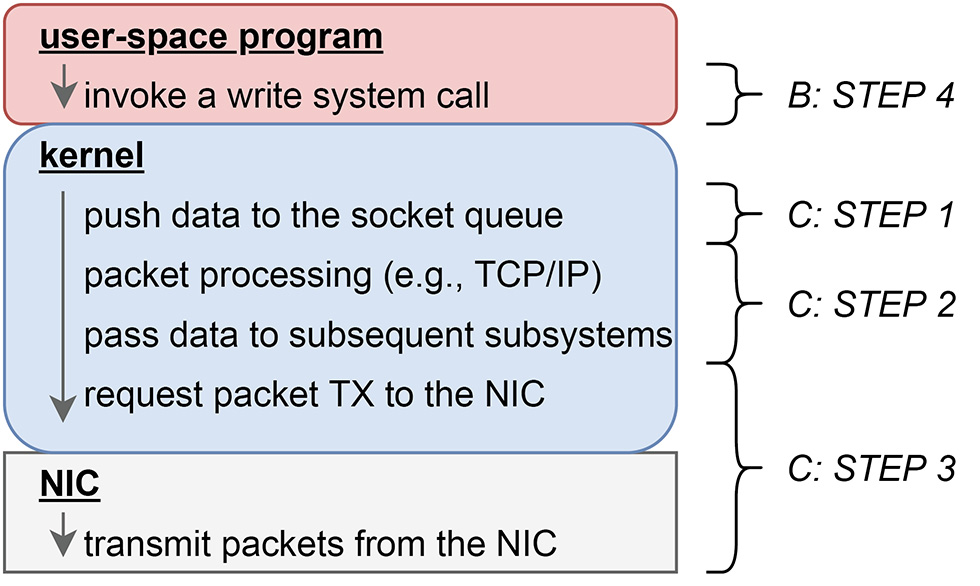
図-1を元に汎用OS環境での通信処理について見ていきます。
基本的なシステム構成
大まかに、図-1中、上から
- (1)ユーザ空間で動作するアプリケーションプログラム
- (2)ネットワークスタックとデバイスドライバを実装しているカーネル
- (3)パケットの送受信を行うNIC
の3つを主な構成要素とします。
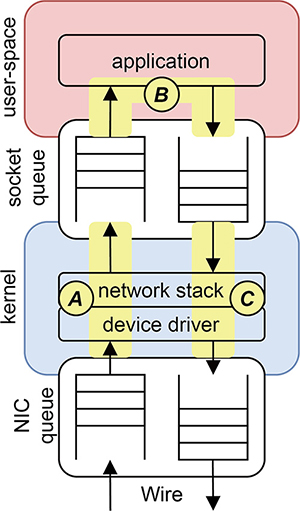
図-1 汎用OS環境での通信関連ソフトウェアの構成
典型的なループ
サーバと呼ばれるような、クライアントのリクエストに対して応答を返すようなプログラムは典型的にA:カーネル空間での受信処理、B:ユーザ空間でのアプリケーション固有の処理、C:カーネル空間での送信処理のループになります。
また、受信と送信処理を実行コンテキストごとにまとめると図-2、図-3のようになります。
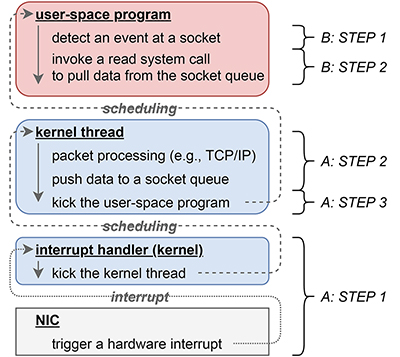
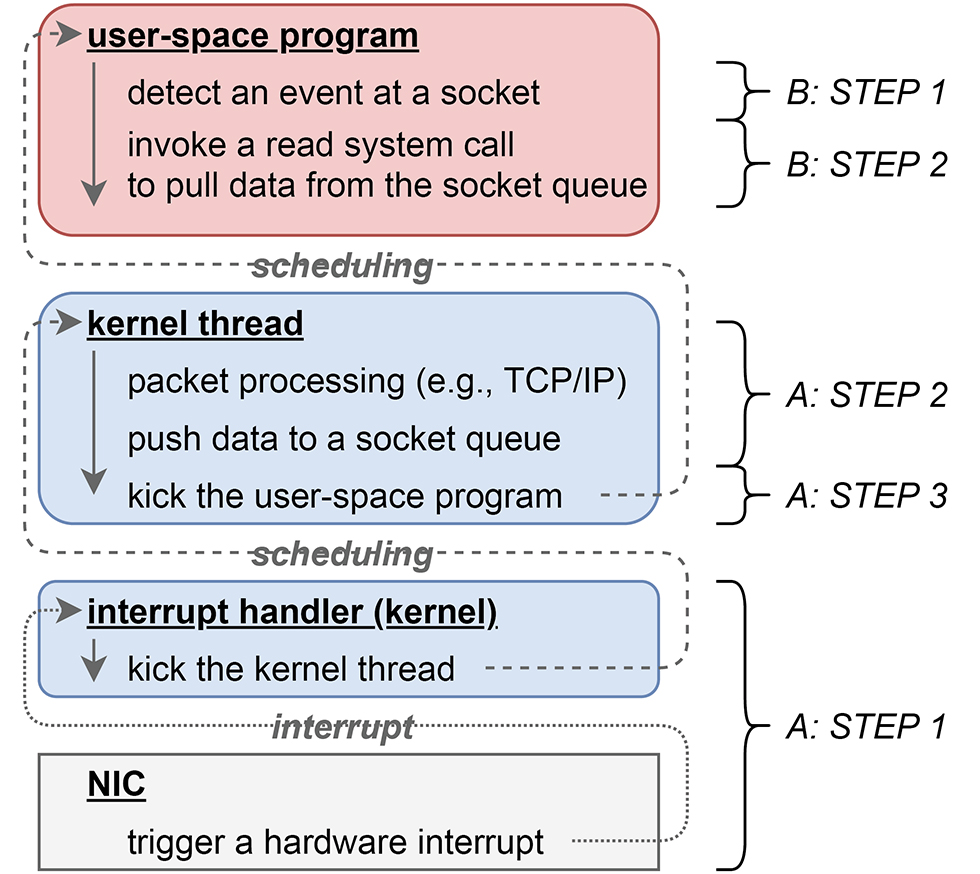
A:カーネル空間での受信処理
- STEP1 ハードウェア(NIC)からの通知
- NICが新しいパケットを受信すると、これをソフトウェアへ通知するために、CPUに対してハードウェア割り込みを発生させます。これにより、CPUでそれまで実行されていたプログラムは中断され、カーネルが事前に設定していたハードウェア割り込みハンドラへ処理が切り替わります。ハードウェア割り込みハンドラは、実装依存ですが、ある程度一般的な処理として、受信パケットを処理するためのカーネルスレッドを起動します。
- STEP2 受信パケットの処理
- 上記ステップ1で起動された受信パケット処理用のカーネルスレッドが、受信パケットのヘッダを読み取り、対応する処理を行います。例えば受信したのがTCPパケットであれば、対応するコネクションについてのTCPのACK番号確認などの状態処理を行い、そのコネクションに紐づけられているソケットのキューに受信パケットを追加します。
- STEP3 ユーザ空間プロセスへの通知
- 上記ステップ2において、特定のソケットのキューにデータや新しいコネクションを追加した場合、そのソケットに紐づいているユーザ空間プロセス・スレッドが、新規入力に備えてselectやpoll、epoll_waitもしくはread系列のシステムコール(例:read、recvmsgなど)で待機している(ブロックされた)状態であれば、それを起動(ブロックを解除)します。
B:ユーザ空間でのプログラムの処理
- STEP1 入力イベントの待機と検知
- ユーザ空間で動作するサーバプログラムの多くは、selectやpoll、epoll_waitまたはread系列のシステムコールで監視対象のソケット(ファイルデスクリプタ)への新規入力を、実行を停止(ブロック)された状態で待機します。監視対象のソケットに入力があれば、前述Aのカーネル空間での受信処理ステップ3によって、待機状態(ブロック)が解除されます。また、select、poll、epoll_waitのようなシステムコールはブロックの解除・リターンに併せて、どのソケット(ファイルデスクリプタ)について入力イベントがあったかの情報がカーネルから渡されます。
- STEP2 カーネルからユーザ空間へのデータの受け渡し
- ユーザ空間プログラムは、上記ステップ1で得られた入力イベントが検知されたソケット(ファイルデスクリプタ)へ向けて、read系列のシステムコールを発行し、前述Aのカーネル空間での受信処理ステップ2によって追加された、ソケットの受信キューに入っているデータを、カーネルからユーザ空間へコピーしてもらいます。
- STEP3 アプリケーション固有の処理
- 上記ステップ2にて受信したデータに対してアプリケーションプログラム固有の処理を行います。例えば、Webサーバであれば、受信したデータをパースしリクエスト内容を判別した上で、そのリクエストに対応する応答のデータを生成します。
- STEP4 カーネルへデータの送信をリクエスト
- ソケット(ファイルデスクリプタ)に対してwrite系列のシステムコール(例:write、sendmsgなど)を発行し、上の処理ステップ3によって用意されたデータの送信をカーネルに対してリクエストします。
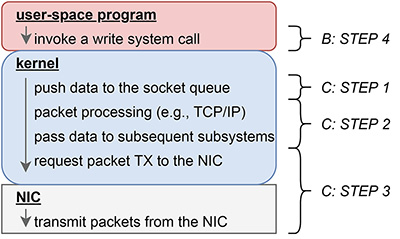
C:カーネル空間での送信処理
- STEP1 ユーザ空間からカーネルへのデータの受け渡し
- Bのステップ4で呼び出されたwrite系列のシステムコールによって、処理がカーネル空間に切り替わります。その後、カーネルはユーザ空間プログラムが用意したデータをカーネル空間にコピーし、それをユーザ空間プログラムが指定したソケットに紐づいている送信キューに追加します。
- STEP2 プロトコルに応じたヘッダ処理
- ステップ1と同じカーネルのコンテキストで、必要であれば転送対象のデータに対してパケットヘッダ付与の処理などを行います。その後、パケットとして準備が完了し、かつ、カーネル内部のサブシステムがそのデータを転送して良いと思ったタイミングで、次のサブシステムに引き渡されます(注1)。
- STEP3 NICからデータの転送
- ヘッダが付与されたデータは最終的にNICのデバイスドライバに引き渡され、デバイスドライバはNICに対してそのデータの送信をリクエストします。
2.2.2 仮想マシンのネットワークI/O
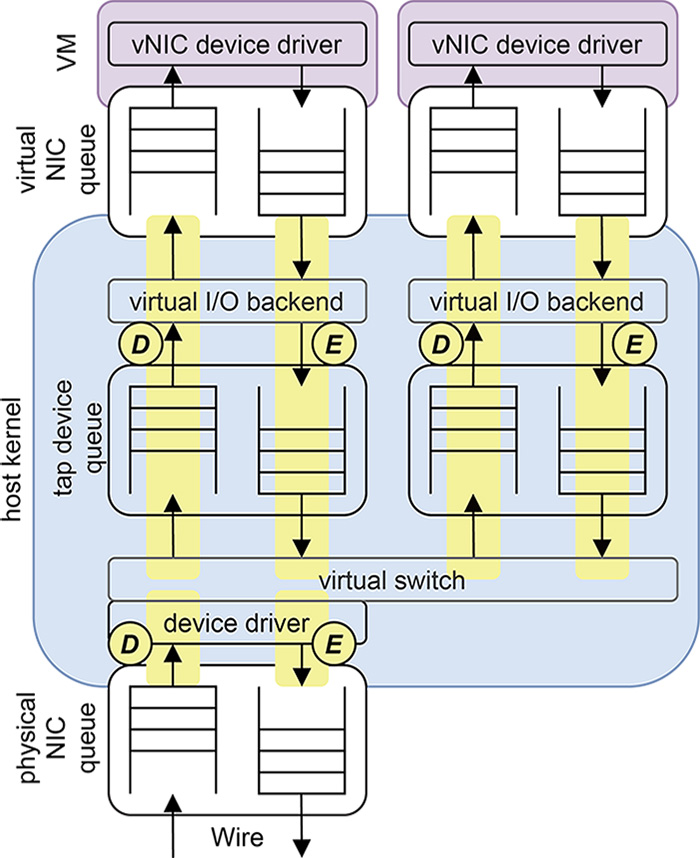
図-4を元に、仮想マシン環境における通信処理の内容について見ていきます。
基本的なシステム構成
大まかに、図-1中、上から
- (1)仮想マシン
- (2)仮想マシンに割り当てられる仮想NIC
- (3)仮想I/Oを行うバックエンド、tapデバイス、仮想スイッチ、デバイスドライバを実装するホストカーネル
- (4)物理NIC
の4点とします。仮想マシンの通信機能の実装形式は何通りか存在しますが、今回はホストカーネル内部のスレッドが仮想I/Oのバックエンドとして機能するLinuxのvhost-netのような形式を想定しています。
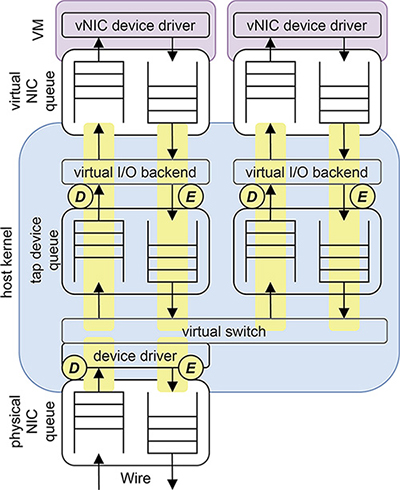
図-4 仮想マシンの通信機構
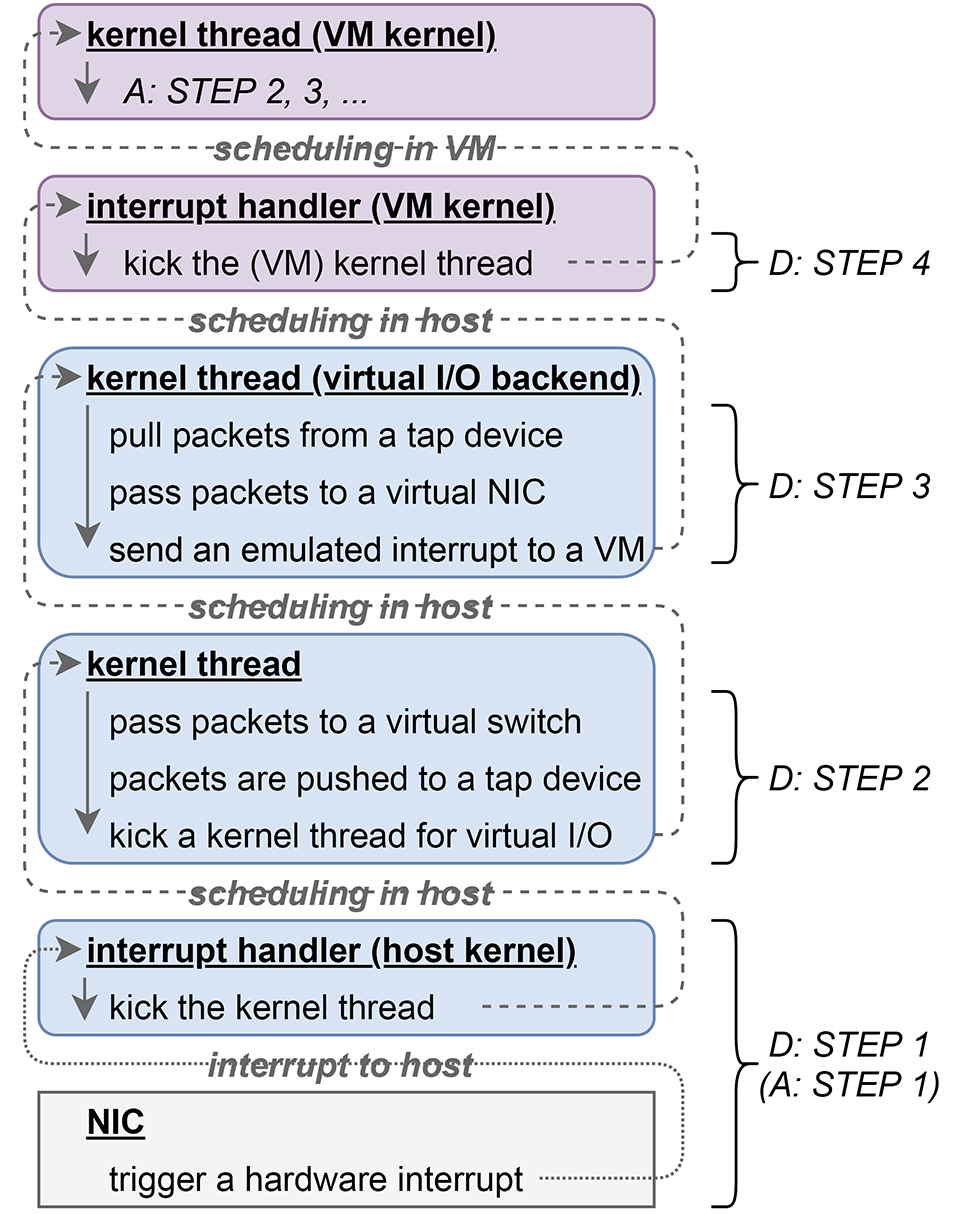
典型的なループ
仮想マシン上で、前節で述べたような、受信したリクエストに対して返信するといったプログラムが動作している場合、仮想マシン環境では典型的に、D:ホスト内での仮想マシン通信の受信処理、前述A~C:仮想マシン上で、汎用OSによる通信関連の処理(注2)、E:ホスト内で仮想マシン通信の送信処理のループが実行されます。
受信と送信処理を実行コンテキストごとにまとめると次の図-5、図-6のようになります。
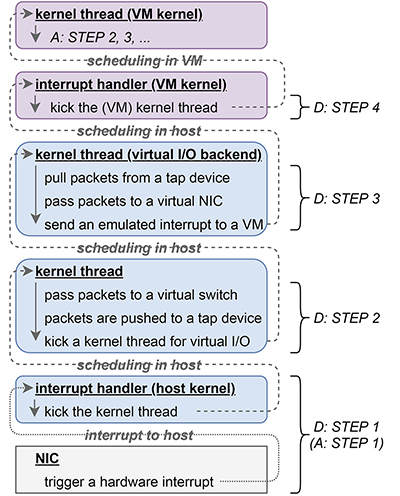
D:仮想マシン通信の受信処理
- STEP1 ハードウェア(物理NIC)からの通知
- 物理NICにパケットが到着したときの最初の処理は、前述Aのステップ1と同じで、ホストカーネル内でハードウェア割り込みハンドラが起動し、受信パケットを処理するためのカーネルスレッドが起動されます。
- STEP2 受信パケットを仮想スイッチに渡す
- 前述Aのステップ2と同じく、ステップ1で起動されたカーネルスレッドが受信パケットを処理しますが、その処理内容は、前述Aの時とは異なります。まず、受信パケットは仮想スイッチへ渡されます。仮想スイッチは受信パケットのEthernetヘッダを読み取り、そのパケットの適切な宛先のインタフェースを見つけ、そのインタフェースの受信キューにパケットを追加します。ここで、宛先インタフェースがtapデバイスであった場合、そのtapデバイスに紐づけられた、仮想I/Oを担当するバックエンドのカーネルスレッドを起動します。
- STEP3 仮想NICへ受信データを渡す
- 上述ステップ2で起動された仮想I/Oを担当するバックエンドのカーネルスレッドが、tapデバイスからデータを取り出し、仮想NICの受信キューに渡します。その後、仮想NICでパケットが受信されたことを仮想マシンに通知するために、仮想マシンに対して割り込みを送ります。
- STEP4 仮想マシン内で受信処理
- 仮想マシンはステップ3でホストから送られた割り込みを受け取り、仮想マシン内のカーネルが事前に設定していた割り込みハンドラへ処理が切り替わります。以後、仮想マシン内での処理は前述Aのステップ1以降と同じになります。
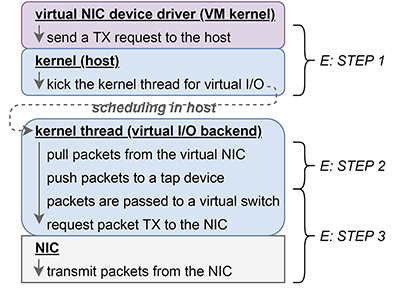
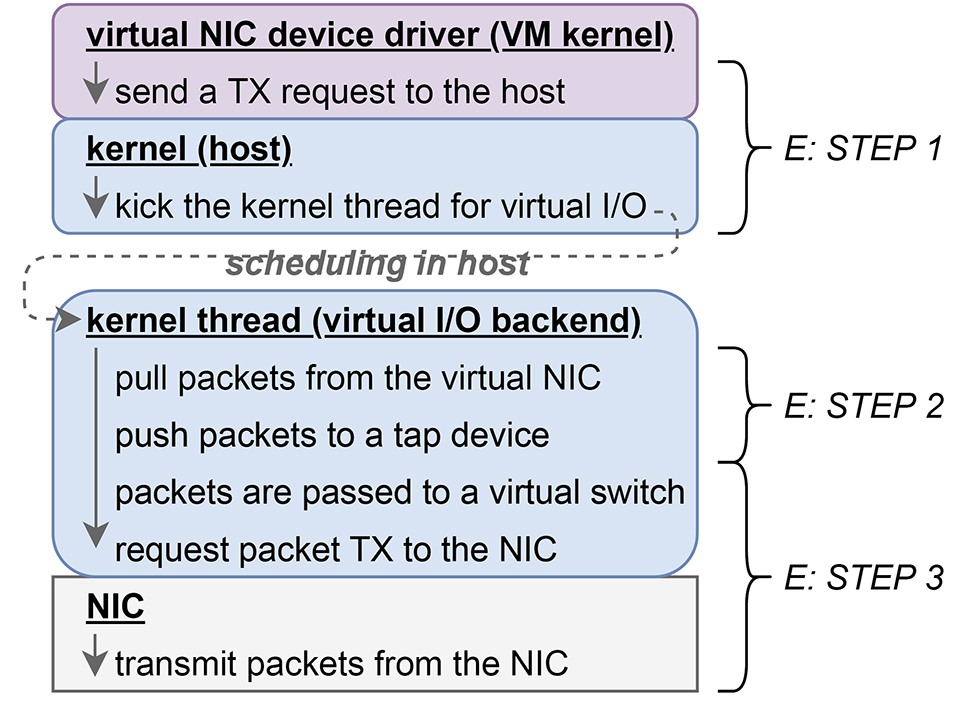
E:仮想マシン通信の送信処理
- STEP1 仮想マシンからのデータ送信リクエスト
- 仮想マシンが前述Cのステップ3を実行して仮想NICデバイスドライバを通して、送信したいデータを仮想NICの送信キューへ追加した後、仮想NICに対してパケット送信をリクエストすると、実行のコンテキストが仮想マシンからホストのカーネルへ切り替わり、その中で仮想I/Oを担当するカーネルスレッドが起動されます。
- STEP2 仮想NICからtapデバイスへデータの受け渡し
- 上記ステップ1で起動された仮想I/Oを担当するカーネルスレッドは、仮想NICの送信キューに入っているデータを取り出し、tapデバイスに引き渡します。
- STEP3 tapデバイスから仮想スイッチへデータの受け渡し
- 上述ステップ2の後、tapデバイスを通じてパケットは仮想スイッチに渡され、パケットの宛先に応じたインタフェースから送信されます。
2.3 研究コミュニティでの取り組み
ここでは、前節で見てきたようなワークロードを高速化するために研究コミュニティが行ってきた取り組みについてまとめます。
2.3.1 システムコール呼び出しコストの削減
NICのI/Oが高速であればあるほど、CPUリソースが追いつく限り前節Bにて前述したようなユーザ空間でのプログラムの処理のループが頻繁に繰り返されることになります。ここでポイントなのが、システムコールはユーザ空間とカーネル空間でコンテキストを切り替える処理が含まれるため、CPUにとって負荷の高い操作であるという点です。具体的に、前節Bで触れたワークロードではステップ1でselect、poll、epoll_waitシステムコール、ステップ2でread系列のシステムコール、ステップ4でwrite系列のシステムコールというようにシステムコールを頻繁に繰り返し呼び出すため、全体のプログラム実行時間の中で、コンテキスト切り替えのために費やされる時間の割合が大きくなってしまうという課題があります。
複数のシステムコールをまとめて発行
2010年にFlexSC(注3)という、複数のカーネルに対する処理のリクエストをひとまとめにして(バッチして)カーネルに対して送ることができるシステムが提案されました。仕組みとしては、ユーザ空間とカーネル空間で共有メモリを作成し、ユーザ空間から実行したいシステムコールとその引数を共有メモリに書き込むと、非同期にカーネル内のスレッドがそのシステムコールを実行して結果を返す、というようになっています。この仕組みにより、システムコールごとにコンテキスト切り替えを発生させなくて済むようになります。このようなアプローチ(注4)は、詳細の実装方法は異なりますが、2.3.3で述べるようなネットワークスタック実装の最適化において広く採用されていきます。
アプリとカーネルの境界をなくす
また、アプリケーションプログラムとOSカーネルを同じアドレス空間で動かす、つまり、アプリケーションとカーネルの境界を取り払ってしまうことで、アプリケーションプログラムからカーネルに実装されている機能を、システムコールではなく、通常の関数呼び出しを通して利用できるようにする、というアプローチも存在します。このような構成は、アプリケーションとカーネルを含むすべてのプログラムを同一のアドレス空間で動かすUnikernels(注7)や、カーネル機能をユーザ空間で動作可能なライブラリとして実装するライブラリOSと呼ばれる仕組みによって実現されます。また、UnikernelsやライブラリOSは、システムコールのコンテキスト切り替えコスト削減による性能の向上に加え、データセンター環境において需要のあるOS機能の起動時間の短縮、メモリ使用量低減、セキュリティ向上などの利点が謳われており、OSv(注8)、IncludeOS(注9)、LightVM(注10)、HermiTux(注11)、Lupin Linux(注12)、Unikraft(注13)、Unikernel Linux(注14)のようなUnikernelsやVirtuOS(注15)、Graphene(注16)、EbbRT(注17)、KylinX(注18)、Demikernel(注19)のようなライブラリOSなど、数多くの研究と実装が発表されています。
2.3.2 ユーザ空間とNIC間のパケット受け渡しの効率化
10Gbps NICが広く使われるようになって、図-1にあるような構成では十分な性能、特に小さいパケットサイズにおいてワイヤーレートを達成するのが難しいということが言われるようになりました。
パケットI/Oフレームワーク
このような課題に対して、2010年代初め頃に、Data PlaneDevelopment Kit(DPDK)(注20)やnetmap(注21)のようなパケットI/Oフレームワークと呼ばれる、ユーザ空間とNICの間で効率的にデータの受け渡しを可能にする仕組みが提案されました。パケットI/Oフレームワークの基本的な機能としては次の2点があります。
- (1)NICに登録している送受信用のパケットバッファを直接ユーザ空間プログラムに貼り付けます。
- (2)ユーザ空間プログラムが
- a)新しくNICが受信したパケットの検知、
- b)NICへパケットの転送をリクエストすることを可能にする軽量なインタフェースを提供します。
プログラムの挙動
ユーザ空間プログラムが上のようなパケットI/Oフレームワークの基本機能を使って前節Bのような、受信したデータに合わせて生成したデータを送信するといった処理を行う場合、以下のような挙動になります。
- STEP1 受信パケットの検知
- 先述のパケットI/Oフレームワークから提供されているインタフェースを使って「新しくNICが受信したパケットの検知」します(注22)。
- STEP2 アプリケーション固有の処理
- 前節Bのステップ3と同じように受信したデータに応じてアプリケーション固有の処理を行います。
- STEP3 NICからのデータ転送
- アプリケーション固有の処理がデータの転送を必要とする場合は、まずユーザ空間に貼り付けられている送信用パケットバッファに送信したいデータを詰め、その後、先述のパケットI/Oフレームワークから提供されているインタフェースを使って「NICへパケット転送をリクエスト」します。
- 注意点
- 上のプログラムの挙動全体は、前節で述べたA・B・Cのすべての処理を置き換え、大幅に簡略化するため、ユーザ空間プログラムとNICの間で非常に高速にデータのやり取りを行うことを可能にしています。ただし、上の挙動にはAのステップ2やCのステップ2にあるようなプロトコルの処理が含まれていないため、そのままではTCP接続経由でデータを配送するようなWebサーバなどを動かすことはできないという点に注意が必要です。
- 削減できるコスト
- 詳細はパケットI/Oフレームワークの実装に依存しますが、例えばDPDK(注20)であれば2.2.1で述べた汎用OS環境と比較して、上の「注意点」にあるようにプロトコル処理が介在しないだけでなく、前節Aのステップ1を起点としたカーネルスレッドのスケジューリング、ステップ3を起点としたユーザ空間プログラム起動に伴うスケジューリング、前節Bのステップ1、2、4に含まれるシステムコール呼び出しとそれに伴うユーザ空間とカーネルの間でのメモリコピー、等々に由来するコストを削減可能です。
- 主な用途
- 「注意点」として先ほど述べたとおり、ユーザ空間プログラムがNICから受け取るデータはTCPのようなプロトコルの処理がされていないものですが、この特性は、ルータのようなネットワーク機能をソフトウェアで実装する場合に都合が良く、NetworkFunction Virtualization(NFV)(注23)というようなコンテキストにおいて、パケットI/Oフレームワークは広く採用されていきました。例を挙げると、研究コミュニティでは、FastClick(注24)、E2(注25)、NetBricks(注26)、Metron(注27)、のようなパケットI/Oフレームワークを利用したNFV基盤が開発されました。また、次節で後述するように、WebサーバなどのアプリケーションプログラムをパケットI/Oフレームワークを組み合わせて利用できるように、パケットI/Oフレームワークの上で動作するプロトコルスタックが開発されています。更に、2.3.4で述べるような、仮想マシンの通信高速化にも利用されていきます。
2.3.3 ネットワークスタック設計の再考
マルチコア環境でスケールさせる
多くのNICは、マルチコア環境で性能をスケールさせることができるように、複数のパケット送受信キューを作成することが可能で、それぞれのCPUコアごとに利用する送受信キューを分けることで、それらキューへアクセスするときのロックの取り合いを避けることを可能にしています。また、多くの高性能なNICはReceive Side Scaling(RSS)と呼ばれるハードウェア機能を実装しており、受信したパケットをTCPのコネクションごとや、IPアドレスを元に特定の受信キューへパケットを振り分け、処理を分散することができるようになっています。ただ、パケットの送受信キューを分けるだけでは不十分で、新しく接続が確立されたTCPコネクションのキューが各ソケットあたり1つずつしかなく、マルチコア環境において並列で同じソケットに対してacceptシステムコールを発行すると性能がスケールしない、という課題がありました。これに対して、Affinity-Accept(注28)、MegaPipe(注29)、Fastsocket(注30)というようなシステムにおいて、TCPコネクションのキューもコアごとに用意する方法が提案され、accept処理のマルチコア環境での性能がスケールできるようになることが示されています。また、MegaPipe(注29)では、2.3.1で触れたFlexSC(注3)を参考に、複数の処理をバッチできるようにしています。
パケットI/Oフレームワークの利用
2.3.2のパケットI/Oフレームワークの「主な用途」として述べたような、パケットI/OフレームワークをWebサーバのようなプログラムの高速化に利用する研究が行われました。具体的には、2.3.2の「プログラムの挙動」のステップ2の中に組み込むことができるTCP/IPのようなプロトコルの実装が行われ、結果として、同じく2.3.2で「削減できるコスト」として述べられたような処理のコストを排除することができるようになり、大幅な高速化が実現しました。研究としては、2014年にSandstorm(注31)とmTCP(注32)というユーザ空間ネットワークスタックが発表されました。mTCP(注32)では上述のFlexSC(注3)で提案されているようなリクエストのバッチに加え、3.3.1にて触れたAffinity-Accept(注28)やMegaPipe(注29)にあるようなTCPコネクションのキューをコアごとに分ける最適化が含まれています。また、同じく2014年にArrakis(注33)とIX(注34)というデバイスを高速に扱えるようにすることを目指した新しいOSが発表されました。これらは共にlwIP(注35)という実装を元にしたネットワークスタックがNICに対して直接I/Oを発行できるようにしています。また、2016年には、パケットの送受信はパケットI/Oフレームワークを使い2.3.2の「プログラムの挙動」を採用しつつ、TCP/IPのプロトコルの処理は前述Aのステップ2やCのステップ2にあるようなカーネルの実装を利用することで成熟したカーネルのTCP/IP実装の恩恵を受けられるようにするStackMap(注36)というシステムが提案されています。2019年にはTAS(注37)という、こちらもDPDK(注20)を利用したユーザ空間で動作するTCPスタック実装が発表されています。2022年にはTAS(注37)とStrata(注38)というファイルシステムを拡張して、既存のアプリケーションに対して変更を加えることなく、I/Oのためのメモリコピーを取り除くことができるようにしたzIO(注39)というシステムが提案されています。また、データセンター内で必要とされる低遅延通信実現のためにZygOS(注40)、Shenango(注41)、Shinjuku(注42)、Caladan(注43)というような、タスクへのCPUコア割り当ての最適化についての研究も行われましたが、これらもDPDK(注20)の上で動作するTCP/IPスタックを採用しています。
ハードウェアへの処理のオフロード
TCPのような処理はコネクションのステートの管理など、比較的複雑な処理が多くCPUにとって負荷が高いため、TCPOffload Engine(TOE)と呼ばれる、NICのようなハードウェアに処理をオフロード可能にするアプローチも模索されてきました。研究コミュニティにおいては、2020年に発表されたAccelTCP(注44)というシステムで、TCPの接続の確立など、特定の状態に関する処理をNICにオフロード可能にすることで、2つのコネクションをつなぎ合わせるspliceのような処理が高速化でき、主にL7ロードバランサーの性能向上に貢献できることを示しています。また、同じく2020年に、Tonic(注45)というNICの中にトランスポート層プロトコルを実装するのに適したハードウェアの設計がなされています。2022年にはFlexTOE(注46)というスマートNICの上で動作するTOE実装が発表され、2023年にはIO-TCP(注47)という、コンテンツ配送ワークロード効率化のために、NICがTCPの処理に加えて直接ストレージデバイスへアクセス可能なようにしたシステムが提案されています。
2.3.4 仮想マシン通信の高速化
前掲の図-4にあるように、仮想マシンの通信においては、物理NICにおけるパケット入出力を多重化する仮想スイッチと、仮想NICのエミュレーションを担当するバックエンドが主なソフトウェアの構成要素となっています。本節では、これら2つの最適化に向けた取り組みについて見ていきます。
仮想スイッチの高速化
2.3.2で触れたパケットI/Oフレームワークは仮想スイッチの高速化において非常にインパクトがあり、過去の研究では、パケットI/Oフレームワークを仮想スイッチの足回りとして適用することで、既存の仕組みと比べて大幅に性能を向上できることが示されました。仮想スイッチは、2.2.2で述べた仮想マシンのI/Oにおいて、Dのステップ2とEのステップ3で実行されるため、仮想スイッチの性能向上は仮想マシンの通信性能の向上に大きく貢献します。研究としては、2012年に、VALE(注48)という2.3.2で触れたnetmap(注21)のAPIの上で動作可能な仮想スイッチ、また、2013年にCuckooSwitch(注49)というDPDK(注20)を足回りに利用した仮想スイッチが提案されています。また、2015年にVALE(注48)の拡張として、mSwitch(注50)が発表されました。広く利用されている仮想スイッチ実装であるOpen vSwitch(注51)でも、この辺りの時期にDPDK(注20)のサポートを追加する取り組みが行われていました。
仮想I/Oバックエンドの改善
研究コミュニティでは、2013年頃に、上述の「仮想スイッチの高速化」にて述べたような仮想スイッチを仮想マシン通信のバックエンドに適用する試みが行われました。その中の1つは、上に述べたVALE(注48)をQEMU(注52)で利用可能なネットワークバックエンドに使うもので、具体的には図-2にある既存のOSカーネルに実装される仮想スイッチを、VALE(注48)スイッチに置き換えることで、仮想マシンのI/O性能を向上できることを示しました(注53)。ですが、この最適化では仮想マシンに付与される仮想NICは既存のものを利用していたため、VALE(注48)との親和性が低く、2.2.2で述べたDのステップ2やEのステップ2において、仮想スイッチと仮想NIC間でのパケットデータのメモリコピーを排除できないなどの欠点があったため、性能についてはまだ向上の余地がありました。この性能向上の余地を埋めるべく、2015年にptnetmap(注54)(注55)というnetmap(注21)インタフェースを直接仮想マシンに対して割り当てる手法がQEMU(注52)/KVM(注56)用に実装され、仮想マシンからでも10Gbps NICの最小パケットサイズでのワイヤーレートである14.88Mppsが達成可能であることが報告されています。また、2014年にはClickOS(注57)という仮想マシンを基本としたNFV基盤の通信を高速化するために、Xen(注6)の仮想マシン通信機構であるnetfront/netbackをVALE(注48) とnetmap(注21)APIを元にした通信機構に置き換える実装が提案されています。更に、同じく2014年にNetVM(注58)という仮想マシンを元にしたNFV基盤が提案されており、こちらはDPDK(注20)をQEMU(注52)/KVM(注56)に適用することで仮想マシンの通信を高速化しています。2017年にはHyperNF(注59)という仕組みにおいて、VALE(注48)を適用した仮想マシン環境でも、前述Eのステップ2にあるようなホスト側で動作するカーネルスレッドと、仮想マシンの仮想CPUを実行するスレッドを別々に分けてしまうことでCPU利用効率が最大化できなくなってしまうという課題に対して、VALE(注48)のような仮想スイッチの処理を、仮想CPUの実行コンテキストに含まれるハイパーコールの中で行うことで、CPU利用効率が向上し、結果として高い仮想マシンの通信性能につながることが示されました。
ハードウェアへの処理のオフロード
多くのNICはSingle Root I/O Virtualization(SR-IOV)(注60)のようなハードウェアでパケットスイッチングを行う機能を実装しており、この機能を利用すると、ソフトウェアによる仮想スイッチ実装と比較して高い性能を発揮できる場合が多いです。一方、SR-IOV(注60)は、ソフトウェアから物理・仮想インタフェース間でのパケット転送について限られた挙動の制御しかできず、データセンターのような複雑な制御が必要な場面では利用が困難な場合がありました。このような課題に対して、2018年にはAccelNet(注61)というスマートNICを使うことでネットワークの制御の柔軟性を高めるシステムの論文が公開されました(AccelNetの商用環境デプロイ自体は2015年から行われていたそうです)。
2.4 IIJ技術研究所における近年の取り組み
本節では、ここまで見てきた過去の研究をふまえ、IIJ技術研究所がどのような取り組みを行っているかについてご紹介します。
2.4.1 新規OS機能と既存のプログラムとの統合方法
前節で見てきたように、10年以上前から研究コミュニティでは、既存の仕組みを置き換えるような、新しいOS機能の設計と実装が発表されてきました。
問題
新しいOS機能を、既存のアプリケーションプログラムに対して「透過的に」適用するためには、システムコールをフックする機構を利用するのが一般的ですが、既存のシステムコールフックの仕組みは、アプリケーションに大幅な性能劣化を引き起こしたり、一部システムコールをフックしそこねる場合があるなどの欠点がありました。これら既存の仕組みの欠点により、特に前節で述べたようなUnikernels・ライブラリOSや新しいネットワークスタック実装の適用範囲が制限されており、結果として、多くの人が研究成果の恩恵を受ける妨げになっているという問題があります。この問題は、既に存在する、ソフトウェアの実行効率を大きく向上し、必要なサーバ数や消費電力を削減できるはずの技術を利用することを困難にしているという側面があります。
解決策
我々は、この問題を解決するために、zpoline(注62)(注63)という、既存の仕組みの欠点を補った、新しいシステムコールフックの仕組みを考案しました。zpoline(注62)(注63)では、syscallとsysenterというそれぞれ2バイトのシステムコールを発行する命令をcallq *%raxという同じく2バイトのcall系列の命令と置き換えると共に、仮想メモリアドレス0番地にトランポリンコードを用意することで、プログラム中のsyscall/sysenterを特定のフック処理へのジャンプに置き換えます。この仕組みの負荷は、ptraceやint3命令を用いたバイナリ書き換えテクニック、またSyscall User Dispatch(注64)のような既存の仕組みと比較して、28~700倍以上小さいという結果になりました。また、これらを使って、広く利用されているキー・バリューストアであるRedis(注65)に対してlwIP(注35)とDPDK(注20)を適用した場合、フックの負荷がほぼ存在しない場合と比べ、既存の仕組みが72.3~98.8%の性能劣化を引き起こすのに対し、提案手法が引き起こす性能劣化は5.2%に留めることができました。
2.4.2 仮想マシンのI/O高速化
この10年の間に仮想マシンの通信性能は大幅に向上しました。一方で、課題もあります。
問題
仮想マシン環境において性能劣化の原因の1つとされる、仮想マシンコンテキストから出る(exitする)コストは、まだ取り除かれておらず、結果として、具体的には2.2.2に述べたEのステップ1で発生するexitによりI/O性能が低下し、仮想マシン上で動作するワークロードの性能を制限してしまう、という問題があります。仮想マシンのI/O性能自体が低い場合、2.3.1や2.3.3で述べられたような仕組みを使って仮想マシン上で動作するネットワークに関わる処理を効率化しても、達成可能な最大の性能が制限されてしまうため、多くの計算がデータセンター内の仮想マシンで実行されている現状においてこの問題は重要です。
解決策
この問題に対して、我々は、仮想マシンが、仮想マシンコンテキストから出る(exitする)ことなく、仮想マシン間で共有されているNICへアクセスすることを可能にするExit-Less、Isolated、and Shared Access(ELISA)(注66)(注67)という仕組みを提案しました。提案手法では、VMFUNCというCPU命令を用いることで、仮想マシン内で、ホストが許可した挙動のみを行うことができる新しいコンテキストを作ることができ、その新しいコンテキストの中でのみNICにアクセスできるようにすることで、仮想マシンがNICを通じて悪意のある挙動を行うことを防ぎます。また、提案手法ではソフトウェアで仮想マシンがデバイスにアクセスする方法を実装するため、SR-IOV(注60)より高い挙動の柔軟性を提供できます。提案手法を用いて仮想マシン通信機能を実装することで、仮想マシンのI/Oリクエストごとに仮想マシンコンテキストからexitするHyperNF(注59)と同様の仕組みと比較して、最大163%性能を向上できました。
2.5 まとめ
システムソフトウェアの通信機能についてある程度一般的な挙動について触れた上で、2010年代初頭からのシステムソフトウェアの通信分野の過去の研究がどのようにそれらを改善してきたかについて振り返りました。また、それらをふまえた近年のIIJ技術研究所での取り組みをご紹介しました。
- (注1)TCPソケット(ファイルデスクリプタ)に対するwriteシステムコール呼び出し時には、ユーザ空間プログラムが指定したデータがNICから発信されるまでに至らない場合があります。例えば、その理由として、TCP実装の輻輳制御や、性能向上のために特定サイズまで送信バッファが埋まるのを待つNagleアルゴリズム、また、NICの帯域制御を担当するqdiscのようなサブシステムがデータの送信を遅延させる場合が考えられます。
- (注2) 仮想マシン上で汎用OSを実行している場合、仮想マシン内の通信プログラムの挙動は基本的に2.2.1で述べられたものと同じになります。
- (注3)Livio Soares and Michael Stumm. 2010. FlexSC: Flexible System Call Scheduling with Exception-Less System Calls. In 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI 10).(https://www.usenix.org/conference/osdi10/flexsc-flexible-system-call-scheduling-exception-less-system-calls)。
- (注4)リクエストを複数をまとめて発行することでドメイン間のコンテキスト切り替えを削減するというアイデアはFlexSC(注3)以前にはコンパイラ(注5)やハイパーバイザ(注6)においてmulti-callと呼ばれるような仕組みで模索されていたそうです。
- (注5)Mohan Rajagopalan, Saumya K. Debray, Matti A. Hiltunen, and Richard D. Schlichting. 2003. Cassyopia: Compiler Assisted System Optimization. In Proceedings of the 9th Conference on Hot Topics in Operating Systems - Volume 9 (HotOS ’03), 18.
- (注6)Paul Barham, Boris Dragovic, Keir Fraser, Steven Hand, Tim Harris, Alex Ho, Rolf Neugebauer, Ian Pratt, and Andrew Warfield. 2003. Xen and the Art of Virtualization. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles (SOSP ’03), 164-177.(https://doi.org/10.1145/945445.945462)。
- (注7)Anil Madhavapeddy, Richard Mortier, Charalampos Rotsos, David Scott, Balraj Singh, Thomas Gazagnaire, Steven Smith, Steven Hand, and Jon Crowcroft. 2013. Unikernels: Library Operating Systems for the Cloud. In Proceedings of the Eighteenth International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’13), 461-472.(https://doi.org/10.1145/2451116.2451167)。
- (注8)Avi Kivity, Dor Laor, Glauber Costa, Pekka Enberg, Nadav Har’El, Don Marti, and Vlad Zolotarov. 2014. OSv - Optimizing the Operating System for Virtual Machines. In 2014 USENIX Annual Technical Conference (USENIX ATC 14), 61-72.(https://www.usenix.org/conference/atc14/technical-sessions/presentation/kivity)。
- (注9)Alfred Bratterud, Alf-Andre Walla, Hårek Haugerud, Paal E. Engelstad, and Kyrre Begnum. 2015. IncludeOS: A Minimal, Resource Efficient Unikernel for Cloud Services. In 2015 IEEE 7th International Conference on Cloud Computing Technology and Science (CloudCom), 250-257.(https://doi.org/10.1109/CloudCom.2015.89)。
- (注10)Filipe Manco, Costin Lupu, Florian Schmidt, Jose Mendes, Simon Kuenzer, Sumit Sati, Kenichi Yasukata, Costin Raiciu, and Felipe Huici. 2017. My Vm Is Lighter (and Safer) Than Your Container. In Proceedings of the 26th Symposium on Operating Systems Principles (SOSP ’17), 218-233.(https://doi.org/10.1145/3132747.3132763)。
- (注11)Pierre Olivier, Daniel Chiba, Stefan Lankes, Changwoo Min, and Binoy Ravindran. 2019. A Binary-Compatible Unikernel. In Proceedings of the 15th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments (VEE 2019), 59-73.(https://doi.org/10.1145/3313808.3313817)。
- (注12)Hsuan-Chi Kuo, Dan Williams, Ricardo Koller, and Sibin Mohan. 2020. A Linux in Unikernel Clothing. In Proceedings of the Fifteenth European Conference on Computer Systems (EuroSys ’ 20).(https://doi.org/10.1145/3342195.3387526)。
- (注13)Simon Kuenzer, Vlad-Andrei Badoiu, Hugo Lefeuvre, Sharan Santhanam, Alexander Jung, Gaulthier Gain, Cyril Soldani, Costin Lupu, Stefan Teodorescu, Costi Raducanu, Cristian Banu, Laurent Mathy, Razvan Deaconescu, Costin Raiciu, and Felipe Huici. 2021. Unikraft: Fast, Specialized Unikernels the Easy Way. In Proceedings of the Sixteenth European Conference on Computer Systems (EuroSys ’21), 376-394.(https://doi.org/10.1145/3447786.3456248)。
- (注14)Ali Raza, Thomas Unger, Matthew Boyd, Eric B Munson, Parul Sohal, Ulrich Drepper, Richard Jones, Daniel Bristot De Oliveira, Larry Woodman, Renato Mancuso, Jonathan Appavoo, and Orran Krieger. 2023. Unikernel Linux (UKL). In Proceedings of the Eighteenth European Conference on Computer Systems (EuroSys ’23), 590-605.(https://doi.org/10.1145/3552326.3587458)。
- (注15)Ruslan Nikolaev and Godmar Back. 2013. VirtuOS: An Operating System with Kernel Virtualization. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles (SOSP ’13), 116-132.(https://doi.org/10.1145/2517349.2522719)。
- (注16)Chia-Che Tsai, Kumar Saurabh Arora, Nehal Bandi, Bhushan Jain, William Jannen, Jitin John, Harry A. Kalodner, Vrushali Kulkarni, Daniela Oliveira, and Donald E. Porter. 2014. Cooperation and Security Isolation of Library OSes for Multi-Process Applications. In Proceedings of the Ninth European Conference on Computer Systems (EuroSys ’14).(https://doi.org/10.1145/2592798.2592812)。
- (注17)Dan Schatzberg, James Cadden, Han Dong, Orran Krieger, and Jonathan Appavoo. 2016. EbbRT: A Framework for Building Per-Application Library Operating Systems. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), 671-688.(https://www.usenix.org/conference/osdi16/technical-sessions/presentation/schatzberg)。
- (注18)Yiming Zhang, Jon Crowcroft, Dongsheng Li, Chengfen Zhang, Huiba Li, Yaozheng Wang, Kai Yu, Yongqiang Xiong, and Guihai Chen. 2018. KylinX: A Dynamic Library Operating System for Simplified and Efficient Cloud Virtualization. In 2018 USENIX Annual Technical Conference (USENIX ATC 18), 173-186.(https://www.usenix.org/conference/atc18/presentation/zhang-yiming)。
- (注19)Irene Zhang, Amanda Raybuck, Pratyush Patel, Kirk Olynyk, Jacob Nelson, Omar S. Navarro Leija, Ashlie Martinez, Jing Liu, Anna Kornfeld Simpson, Sujay Jayakar, Pedro Henrique Penna, Max Demoulin, Piali Choudhury, and Anirudh Badam. 2021. The Demikernel Datapath OS Architecture for Microsecond-Scale Datacenter Systems. In Proceedings of the ACM Sigops 28th Symposium on Operating Systems Principles (SOSP ’21), 195-211.(https://doi.org/10.1145/3477132.3483569)。
- (注20)Intel. 2010. Data Plane Development Kit.(https://www.dpdk.org/)。
- (注21)Luigi Rizzo. 2012. Netmap: A Novel Framework for Fast Packet I/O. In 2012 USENIX Annual Technical Conference (USENIX ATC 12), 101-112.(https://www.usenix.org/conference/atc12/technical-sessions/presentation/rizzo)。
- (注22)新しい受信パケットが検知された場合、そのデータは既にユーザ空間に貼り付けられたパケットバッファ上に存在するため、前節Bのステップ2にあるような処理は不要です。
- (注23)NFVは、それまでネットワーク機能ごとに高価な専用ハードウェアを購入する必要があったところを、汎用コンピュータを使ってソフトウェアでネットワーク機能を実装するようにするもので、単一のコンピュータを複数の用途で利用可能にし、かつ、機能の追加・変更が専用ハードウェアを用いるより容易であるとされています。特に、高速なNICが安価で入手可能になったことはNFVの適用について追い風であったと考えられます。
- (注24)Tom Barbette, Cyril Soldani, and Laurent Mathy. 2015. Fast Userspace Packet Processing. In 2015 ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), 5-16.(https://doi.org/10.1109/ANCS.2015.7110116)。
- (注25)Shoumik Palkar, Chang Lan, Sangjin Han, Keon Jang, Aurojit Panda, Sylvia Ratnasamy, Luigi Rizzo, and Scott Shenker. 2015. E2: A Framework for NFV Applications. In Proceedings of the 25th Symposium on Operating Systems Principles (SOSP ’15), 121-136.(https://doi.org/10.1145/2815400.2815423)。
- (注26)Aurojit Panda, Sangjin Han, Keon Jang, Melvin Walls, Sylvia Ratnasamy, and Scott Shenker. 2016. NetBricks: Taking the V Out of NFV. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), 203-216.(https://www.usenix.org/conference/osdi16/technical-sessions/presentation/panda)。
- (注27)Georgios P. Katsikas, Tom Barbette, Dejan Kostic, Rebecca Steinert, and Gerald Q. Maguire Jr. 2018. Metron: NFV Service Chains at the True Speed of the Underlying Hardware. In 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), 171-186.(https://www.usenix.org/conference/nsdi18/presentation/katsikas)。
- (注28)Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ’12), 337-350.(https://doi.org/10.1145/2168836.2168870)。
- (注29)Sangjin Han, Scott Marshall, Byung-Gon Chun, and Sylvia Ratnasamy. 2012. MegaPipe: A New Programming Interface for Scalable Network I/O. In 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI 12), 135-148.(https://www.usenix.org/conference/osdi12/technical-sessions/presentation/han)。
- (注30)Xiaofeng Lin, Yu Chen, Xiaodong Li, Junjie Mao, Jiaquan He, Wei Xu, and Yuanchun Shi. 2016. Scalable Kernel TCP Design and Implementation for Short-Lived Connections. In Proceedings of the Twenty-First International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’ 16), 339-352.(https://doi.org/10.1145/2872362.2872391)。
- (注31)Ilias Marinos, Robert N. M. Watson, and Mark Handley. 2014. Network Stack Specialization for Performance. In Proceedings of the 2014 ACM Conference on SIGCOMM (SIGCOMM ’14), 175-186.(https://doi.org/10.1145/2619239.2626311)。
- (注32)EunYoung Jeong, Shinae Wood, Muhammad Jamshed, Haewon Jeong, Sunghwan Ihm, Dongsu Han, and KyoungSoo Park. 2014. mTCP: A Highly Scalable User-Level TCP Stack for Multicore Systems. In 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14), 489-502.(https://www.usenix.org/conference/nsdi14/technical-sessions/presentation/jeong)。
- (注33)Simon Peter, Jialin Li, Irene Zhang, Dan R. K. Ports, Doug Woos, Arvind Krishnamurthy, Thomas Anderson, and Timothy Roscoe. 2014. Arrakis: The Operating System Is the Control Plane. In 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI14), 1-16.(https://www.usenix.org/conference/osdi14/technical-sessions/presentation/peter)。
- (注34)Adam Belay, George Prekas, Ana Klimovic, Samuel Grossman, Christos Kozyrakis, and Edouard Bugnion. 2014. IX: A Protected Dataplane Operating System for High Throughput and Low Latency. In 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14), 49-65.(https://www.usenix.org/conference/osdi14/technical-sessions/presentation/belay)。
- (注35)Adam Dunkels. 2001. Design and Implementation of the lwIP TCP/IP Stack. Swedish Institute of Computer Science 2, 77.
- (注36)Kenichi Yasukata, Michio Honda, Douglas Santry, and Lars Eggert. 2016. StackMap: Low-Latency Networking with the OS Stack and Dedicated NICs. In 2016 USENIX Annual Technical Conference (USENIX ATC 16), 43-56.(https://www.usenix.org/conference/atc16/technical-sessions/presentation/yasukata)。
- (注37)Antoine Kaufmann, Tim Stamler, Simon Peter, Naveen Kr. Sharma, Arvind Krishnamurthy, and Thomas Anderson. 2019. TAS: TCP Acceleration as an OS Service. In Proceedings of the Fourteenth EuroSys Conference 2019 (EuroSys ’19).(https://doi.org/10.1145/3302424.3303985)。
- (注38)Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, and Thomas Anderson. 2017. Strata: A Cross Media File System. In Proceedings of the 26th Symposium on Operating Systems Principles (SOSP ’17), 460-477.(https://doi.org/10.1145/3132747.3132770)。
- (注39)Timothy Stamler, Deukyeon Hwang, Amanda Raybuck, Wei Zhang, and Simon Peter. 2022. zIO: Accelerating IO-Intensive Applications with Transparent Zero-Copy IO. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), 431-445.(https://www.usenix.org/conference/osdi22/presentation/stamler)。
- (注40)George Prekas, Marios Kogias, and Edouard Bugnion. 2017. ZygOS: Achieving Low Tail Latency for Microsecond-Scale Networked Tasks. In Proceedings of the 26th Symposium on Operating Systems Principles (SOSP ’17), 325-341.(https://doi.org/10.1145/3132747.3132780)。
- (注41)Amy Ousterhout, Joshua Fried, Jonathan Behrens, Adam Belay, and Hari Balakrishnan. 2019. Shenango: Achieving High CPU Efficiency for Latency-Sensitive Datacenter Workloads. In 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), 361-378.(https://www.usenix.org/conference/nsdi19/presentation/ousterhout)。
- (注42)Kostis Kaffes, Timothy Chong, Jack Tigar Humphries, Adam Belay, David Mazières, and Christos Kozyrakis. 2019. Shinjuku: Preemptive Scheduling for μsecond-scale Tail Latency. In 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), 345-360.(https://www.usenix.org/conference/nsdi19/presentation/kaffes)。
- (注43)Joshua Fried, Zhenyuan Ruan, Amy Ousterhout, and Adam Belay. 2020. Caladan: Mitigating Interference at Microsecond Timescales. In 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), 281-297.(https://www.usenix.org/conference/osdi20/presentation/fried)。
- (注44)YoungGyoun Moon, SeungEon Lee, Muhammad Asim Jamshed, and KyoungSoo Park. 2020. AccelTCP: Accelerating Network Applications with Stateful TCP Offloading. In 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20), 77-92.(https://www.usenix.org/conference/nsdi20/presentation/moon)。
- (注45)Mina Tahmasbi Arashloo, Alexey Lavrov, Manya Ghobadi, Jennifer Rexford, David Walker, and David Wentzlaff. 2020. Enabling Programmable Transport Protocols in High-Speed NICs. In 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20), 93-109.(https://www.usenix.org/conference/nsdi20/presentation/arashloo)。
- (注46)Rajath Shashidhara, Tim Stamler, Antoine Kaufmann, and Simon Peter. 2022. FlexTOE: Flexible TCP Offload with Fine-Grained Parallelism. In 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), 87-102.(https://www.usenix.org/conference/nsdi22/presentation/shashidhara)。
- (注47)Taehyun Kim, Deondre Martin Ng, Junzhi Gong, Youngjin Kwon, Minlan Yu, and KyoungSoo Park. 2023. Rearchitecting the TCP Stack for I/O-Offloaded Content Delivery. In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), 275-292.(https://www.usenix.org/conference/nsdi23/presentation/kim-taehyun)。
- (注48)Luigi Rizzo and Giuseppe Lettieri. 2012. VALE, a Switched Ethernet for Virtual Machines. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies (CoNEXT ’12), 61-72.(https://doi.org/10.1145/2413176.2413185)。
- (注49)Dong Zhou, Bin Fan, Hyeontaek Lim, Michael Kaminsky, and David G. Andersen. 2013. Scalable, High Performance Ethernet Forwarding with CuckooSwitch. In Proceedings of the Ninth ACM Conference on Emerging Networking Experiments and Technologies (CoNEXT ’13), 97-108.(https://doi.org/10.1145/2535372.2535379)。
- (注50)Michio Honda, Felipe Huici, Giuseppe Lettieri, and Luigi Rizzo. 2015. mSwitch: A Highly-Scalable, Modular Software Switch. In Proceedings of the 1st ACM SIGCOMM Symposium on Software Defined Networking Research (SOSR ’15).(https://doi.org/10.1145/2774993.2775065)。
- (注51)Ben Pfaff, Justin Pettit, Teemu Koponen, Ethan Jackson, Andy Zhou, Jarno Rajahalme, Jesse Gross, Alex Wang, Joe Stringer, Pravin Shelar, Keith Amidon, and Martin Casado. 2015. The Design and Implementation of Open vSwitch. In 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI 15), 117-130.(https://www.usenix.org/conference/nsdi15/technical-sessions/presentation/pfaff)。
- (注52)Fabrice Bellard. 2005. QEMU, a Fast and Portable Dynamic Translator. In 2005 USENIX Annual Technical Conference (USENIX ATC 05), 41-46.(https://www.usenix.org/conference/2005-usenix-annual-technical-conference/qemu-fast-and-portable-dynamic-translator)。
- (注53)Luigi Rizzo, Giuseppe Lettieri, and Vincenzo Maffione. 2013. Speeding up Packet I/O in Virtual Machines. In Architectures for Networking and Communications Systems, 47-58.(https://doi.org/10.1109/ANCS.2013.6665175)。
- (注54)Stefano Garzarella, Giuseppe Lettieri, and Luigi Rizzo. 2015. Virtual Device Passthrough for High Speed Vm Networking. In 2015 ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), 99-110.(https://doi.org/10.1109/ANCS.2015.7110124)。
- (注55)Vincenzo Maffione, Luigi Rizzo, and Giuseppe Lettieri. 2016. Flexible Virtual Machine Networking Using Netmap Passthrough. In 2016 IEEE International Symposium on Local and Metropolitan Area Networks (LANMAN), 1-6.(https://doi.org/10.1109/LANMAN.2016.7548852)。
- (注56)Avi Kivity, Yaniv Kamay, Dor Laor, Uri Lublin, and Anthony Liguori. 2007. KVM: the Linux Virtual Machine Monitor. In Proceedings of the 2007 Ottawa Linux Symposium (OLS ’07).
- (注57)Joao Martins, Mohamed Ahmed, Costin Raiciu, Vladimir Olteanu, Michio Honda, Roberto Bifulco, and Felipe Huici. 2014. ClickOS and the Art of Network Function Virtualization. In 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14), 459-473.(https://www.usenix.org/conference/nsdi14/technical-sessions/presentation/martins)。
- (注58)Jinho Hwang, K. K. Ramakrishnan, and Timothy Wood. 2014. NetVM: High Performance and Flexible Networking Using Virtualization on Commodity Platforms. In 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14), 445-458.(https://www.usenix.org/conference/nsdi14/technical-sessions/presentation/hwang)。
- (注59)Kenichi Yasukata, Felipe Huici, Vincenzo Maffione, Giuseppe Lettieri, and Michio Honda. 2017. HyperNF: Building a High Performance, High Utilization and Fair NFV Platform. In Proceedings of the 2017 Symposium on Cloud Computing (SoCC ’17), 157-169.(https://doi.org/10.1145/3127479.3127489)。
- (注60)PCI-SIG. 2010. Single Root I/O Virtualization and Sharing Specification.(https://pcisig.com/specifications/iov/single_root/)。
- (注61)Daniel Firestone, Andrew Putnam, Sambhrama Mundkur, Derek Chiou, Alireza Dabagh, Mike Andrewartha, Hari Angepat, Vivek Bhanu, Adrian Caulfield, Eric Chung, Harish Kumar Chandrappa, Somesh Chaturmohta, Matt Humphrey, Jack Lavier, Norman Lam, Fengfen Liu, Kalin Ovtcharov, Jitu Padhye, Gautham Popuri, Shachar Raindel, Tejas Sapre, Mark Shaw, Gabriel Silva, Madhan Sivakumar, Nisheeth Srivastava, Anshuman Verma, Qasim Zuhair, Deepak Bansal, Doug Burger, Kushagra Vaid, David A. Maltz, and Albert Greenberg. 2018. Azure Accelerated Networking: SmartNICs in the Public Cloud. In 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), 51-66.(https://www.usenix.org/conference/nsdi18/presentation/firestone)。
- (注62)Kenichi Yasukata. 2021. システムコールを速く漏れなくフックする方法. IIJ Engineers Blog.(https://eng-blog.iij.ad.jp/archives/11169)。
- (注63)Kenichi Yasukata, Hajime Tazaki, Pierre-Louis Aublin, and Kenta Ishiguro. 2023. zpoline: a system call hook mechanism based on binary rewriting. In 2023 USENIX Annual Technical Conference (USENIX ATC 23), 293-300.(https://www.usenix.org/conference/atc23/presentation/yasukata)。
- (注64)Gabriel Krisman Bertazi. 2021. Syscall User Dispatch.(https://www.kernel.org/doc/html/latest/admin-guide/syscall-user-dispatch.html)。
- (注65)Salvatore Sanfilippo. 2009. Redis - Remote Dictionary Server.(https://redis.io/)。
- (注66)Kenichi Yasukata. 2023. 【国際学会 ASPLOS 2023】論文採択までの道のり~仮想マシン間のメモリ領域共有に関する課題と解決策~ . IIJ Engineers Blog.(https://eng-blog.iij.ad.jp/archives/18819)。
- (注67)Kenichi Yasukata, Hajime Tazaki, and Pierre-Louis Aublin. 2023. Exit-Less, Isolated, and Shared Access for Virtual Machines. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 (ASPLOS 2023), 224-237.(https://doi.org/10.1145/3582016.3582042)。
執筆者プロフィール
安形 憲一 (やすかた けんいち)
IIJ 技術研究所 技術研究室。
システムソフトウェアの研究に取り組んでいます。
- 2. フォーカス・リサーチ(1) システムソフトウェアの通信分野における2010年頃からの研究まとめ
ここからフッターメニューです




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- © Internet Initiative Japan Inc.
ページの終わりです